› Forums › Music › Sound Engineering › How to Build a Sound System
- This topic has 48 replies, 11 voices, and was last updated September 8, 2011 at 12:16 am by joshd96320.
-
AuthorPosts
-
November 2, 2007 at 7:38 am #1042781
Building a Sound System: How To Guide
Part 1
Disclaimer: This series of posts is firstly intended to help teach budding rig builders and people interested in sound engineering how to go about it…..I’ve been a sound engineer for nearly fifteen years now, and these how to’s are likely to approach perilously close to a doorstop style textbook… You have been warned 😉 They will take a while to finish, and likely will always be a “work in progress” too (there are always new things to learn after all, and I will continue updating as I do…) The information contained here is as accurate as my knowledge of the subject currently, and any errors are entirely my fault (although I take no responsibility for information in external links, or bits written by other people).
You use the information at your own risk, and I will be presuming a basic level of technical skill. To build a rig, you will at the very least need some electrical/electronics skill, and decent wood working skills will also be helpful. It’s beyond the scope of this document to give you a full electronics primer, or a cabinet building one – if you need these, I can heartily recommend the book “Teach yourself electricity and electronics” by Stan Giblisco and published by McGraw/Hill which is the main text you would likely use if you were to take a college course in the subject. As for the wood working skills, your best bet is to ask a Joiner pal if he can show you what you need (or a friendly DIY nut 😉 )
I will include safety information where important, but I take no responsibility for your use (or lack thereof) of it – but please whatever you do, be aware that the kinds of equipment you are going to be building/configuring have the potential to leave a set of smoking boots where once there was a raver. Amplifiers especially have power supplies that are very unforgiving of mistakes – the reservoir capacitors can hold charge enough to make your screwdriver tip literally explode in a white hot metal shower if shorted in the wrong place. And for many hours after they’ve been turned ‘off’ to boot!! And obviously you may eventually be playing with power supplies well beyond your home mains circuit (which you will need to use if you get a rig bigger than about 4K or so). Common sense is helpful, and I will include a section on rig safety, but a course in electrical safety procedures wouldn’t hurt either….
I’m hoping that the information will be used to spread the free party spirit as far as we can, but you are obviously free to use it as you see fit… From the copyright point of view, my only proviso is that if you do reproduce it, it is made available for free to any who would like to read it – especially if they are planning to use it to build a rave rig 🙂
And if you do use it to build a rig – invite me to your first party…..
And if you think you spot any mistakes, let me know – I am certain to leave things out, and sometimes have trouble getting information from my head into words that make sense to anyone else who doesn’t already know. Shouldn’t be a problem for any trained techie’s, as we’re a fairly argumentative and cantankerous bunch – but don’t be shy if you’re not a techie too. If it’s not a mistake, I’ll try and explain it, and if it is then I get to learn something new 🙂
Anyhow, that’ll do for a disclaimer. Now… Tally ho, and on with the motley 😀
November 2, 2007 at 7:39 am #1124057Basic Audio Theory:
This first section is going to be essentially theory, and will hopefully give you enough of a grounding to understand why we need to do the later practical stuff
Characteristics of an audio wave, and how it is perceived/interpreted by our hearing.
The conventional representation of an audio wave ie – all those very scientific pics that look like this:
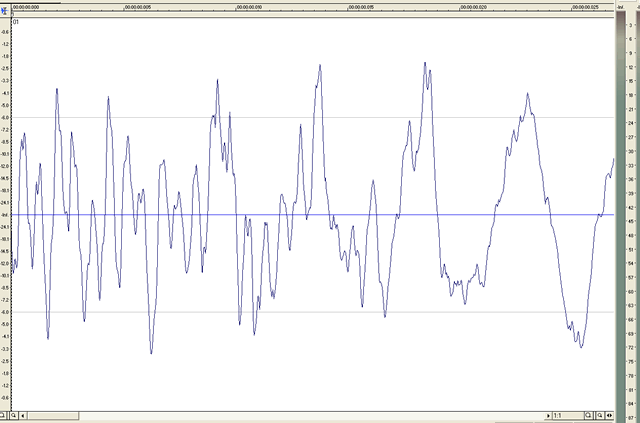
are actually slightly misleading if you are trying to visualise the physical reality of one. It is correct in that it represents audio in the stated way, which is amplitude against time, and it is useful in many ways for analysis and editing, but it also leaves the impression that audio is a transverse wave (like a piece of string oscillating, or waves on a pond after a stone is dropped in). Audio is actually a longitudinal wave, and there are important differences in how they behave. So, though we will be using the above representation as a convenience in other parts of this document (it is called a wave graph), remember that it is only a useful convenience. Audiowaves are difficult to represent in 2 dimensions, as the physical reality is basically 4 dimensional – a set of pressure variations in 3 dimensions, emanating at a set speed from the source (which gives us the 4th dimension).
The major difference in behaviour between the two is the fact that longitudinal waves can propagate through gases and liquids, whereas transverse waves cannot (there is no mechanism for driving motion perpendicular to the propagation of the wave in transverse waves). For a full explanation of why and how, Hyperphysics has a good explanation here.
Because the waves are propagated outward from the source (assuming a point source – ie single point of radiation and no obstacles), audio waves obey the “inverse square law” of physics – basically, each time the distance from the source doubles, the sound pressure is quartered – represented by the equation P/4?r²=I (where P=source power, and I=Sound intensity). This gives an effective logarithmic drop off in the sound intensity as you move away from the source. Again, Hyperphysics has a good explanation of how this works (I will be referring regularly to the Hyperphysics website, and recommend it thoroughly as a source of scientific info generally) The inverse square law is obviously important to us in engineering audio amplification, as much of what we do will involve using other properties of audio waves to mitigate the inverse square characteristic…. I will go into this in more detail later on.
Our hearing mechanism essentially collects these pressure variations, and transmits them, via the tympanic membrane and the tiny bones (or Ossicles), into the inner ear, and Cochlea – which then converts the kinetic motion into electrical impulses to be transmitted to the brain… This is a very simplistic explanation for what is a quite complex set of interactions, and is explained in much more detail here. For our purposes, the other point to take note of along with the fact that our hearing apparatus is a very sensitive system is the action of the auditory canal (the bit that transmits sound from the outer ear onto the tympanic membrane). Because it acts essentially as a closed tube resonator, the auditory canal enhances sound in the range between 2 and 5KHz (which is, coincidentally, also the frequency range of the human voice). This rise in sensitivity is often referred to as the Fletcher/Munson curve (and is used extensively in perceptual compression techniques – ie MP3’s etc). It also causes what is referred to as the bass loss problem – essentially, though all frequencies drop off according to the inverse square law, our hearing makes the drop off of bass frequencies much more pronounced (and means therefore that the bass frequencies need more reinforcement than those in the Fletcher/Munson curve)…
Methods of measuring audio levels.
As you will (hopefully) be aware from the above information, although audio follows measurable physical laws, there is also a lot that is down to subjective interpretation – the size and shape of the ear and auditory canal dictate where maximum sensitivity lies for a particular person (and because we are all different, there is a good deal of variation in these values). The efficiency of all parts of the ear in amplifying the pressure wave and transmitting it to the Cochlea creates variation in perception of overall loudness, and the efficiency of the Cochlea in converting kinetic energy into electrical creates yet more variation…. The question is – how do we create a set of measurements on which we can all agree, and which gives some objective basis of comparison for sound levels? This is an essential question if we hope to have any scientific basis from which to begin engineering our sound reinforcement. It has been answered in a number of ways – none of which are entirely satisfactory, but each of which arrives at some sort of consensus for use as an objective base…. They are:
1) Sound Pressure.
This is the most basic measurement, and also the most objective – it is a measurement of the sound pressure (obviously) at a given point and time in comparison to atmospheric pressure, stated in newtons/m². It is of relatively limited use, because although it is a direct measurement of the pressure wave, it is a limited snapshot at a given time – to be useful we need a measurement of these snapshots over time, or an average level.
2) Sound Intensity.
This is the sound power per unit area, the usual context being a measurement of the average intensity at a given point. It is measured in Watts/m², or acoustic watts. Unlike the sound pressure measurement, this is a measurement of the sound energy at a given point as an average over time.
From this point, we need to relate the subjective sensation of loudness to some objective base. The way this is achieved is by the use of the Decibel scale or dB (named after Alexander Graham Bell – it equals 1/10th of a Bell). The basic premise is – when a sound of intensity I falls on the ear, what change ?I will cause the hearer to report a barely audible change in the sensation of loudness. Our hearing turns out to be so constructed that ?I is proportional to I – that is the more intense the sound, the greater ?I must be. So:
3) The Decibel scale, or dB.
Is a logarithmic scale used to measure loudness relative to a baseline known as the threshold of hearing. The threshold of hearing is an intensity of 10?¹²W/m² – chosen because it is near the lower limit of human audibility. The expression of loudness is then obtained by I(dB)=10log(¹º)[I/Iº], where I=the intensity, and Iº=the threshold of hearing. For an in depth analysis of this calculation, and how it is used, see this page. This scale is a useful measure of loudness, and is the standard measurement used in audio. It is not perfect however, as the human ear’s perception of loudness changes based on frequency (due to the effect of the auditory canal). The dB scale can be altered by use of contour filters (which effectively filter out frequencies that the ear does not hear well in order to more effectively simulate human hearing). Most common of these is the:
4) dBA – dB of sound with an “A” contour filter.
This the most commonly used contour filter, as it most closely mimics the hearing curve of the human ear. See here for a description of how it works – it is the scale generally used to measure the loudness at venues etc, or to measure ambient sound on a site etc.
These are the basic and most common measurements; there are others, either using different contour filters, or more closely relating the loudness by plotting equal loudness curves for the human ear, and then relating a dB value at a set frequency as in the Phon and Sone scales.
5) SPL, or Sound Pressure Level.
This is a measurement commonly used in the specs for speaker drivers, as one axis of a frequency response graph. Basically, the SPL is measured in dB when the speaker or system is fed 1Watt of electrical power, by placing a microphone 1m away – hence the curves shown on driver specs which show the output at varying frequency in dB SPL at 1w/1m. It is useful as a rough guide only, and shouldn’t be used as a guide to speaker driver quality (if you check such ratings, you will notice that mid range and tweeters invariably have higher dB ratings than woofers).
So, that is the basic physics/biology of audio – obviously there is a lot more, but hopefully this information should give you a sound basis. Again, I can recommend to you the Hyperphysics site which contains a huge amount of the theoretical information on sound, along with many of the engineering practices generally used.
For our purposes, and in conclusion we can reiterate the points that are going to be of most use to us in building our rig:
Audio is transmitted through air as a longitudinal wave, and follows the Inverse square law of physics. This logarithmic drop off in sound intensity is what we need to engineer to compensate for.
Our perception mechanism for sound is most sensitive in the human vocal range of 2-5KHz, and shows a marked drop off at the bass frequency range – we therefore need to reinforce these frequencies to compensate.
There are many ways of measuring audio, none of which are entirely satisfactory. The ones we will mostly be using however are: Intensity, measured in Acoustic watts (W/m²). Loudness, measured in dB, and ambient loudness measured using a contour filter (in dBA).
In the next section, we will investigate how audio is created or manipulated for the purpose of amplification.
November 2, 2007 at 7:39 am #1144975Basic Audio Theory:
This first section is going to be essentially theory, and will hopefully give you enough of a grounding to understand why we need to do the later practical stuff
Characteristics of an audio wave, and how it is perceived/interpreted by our hearing.
The conventional representation of an audio wave ie – all those very scientific pics that look like this:
are actually slightly misleading if you are trying to visualise the physical reality of one. It is correct in that it represents audio in the stated way, which is amplitude against time, and it is useful in many ways for analysis and editing, but it also leaves the impression that audio is a transverse wave (like a piece of string oscillating, or waves on a pond after a stone is dropped in). Audio is actually a longitudinal wave, and there are important differences in how they behave. So, though we will be using the above representation as a convenience in other parts of this document (it is called a wave graph), remember that it is only a useful convenience. Audiowaves are difficult to represent in 2 dimensions, as the physical reality is basically 4 dimensional – a set of pressure variations in 3 dimensions, emanating at a set speed from the source (which gives us the 4th dimension).
The major difference in behaviour between the two is the fact that longitudinal waves can propagate through gases and liquids, whereas transverse waves cannot (there is no mechanism for driving motion perpendicular to the propagation of the wave in transverse waves). For a full explanation of why and how, Hyperphysics has a good explanation here.
Because the waves are propagated outward from the source (assuming a point source – ie single point of radiation and no obstacles), audio waves obey the “inverse square law” of physics – basically, each time the distance from the source doubles, the sound pressure is quartered – represented by the equation P/4?r²=I (where P=source power, and I=Sound intensity). This gives an effective logarithmic drop off in the sound intensity as you move away from the source. Again, Hyperphysics has a good explanation of how this works (I will be referring regularly to the Hyperphysics website, and recommend it thoroughly as a source of scientific info generally) The inverse square law is obviously important to us in engineering audio amplification, as much of what we do will involve using other properties of audio waves to mitigate the inverse square characteristic…. I will go into this in more detail later on.
Our hearing mechanism essentially collects these pressure variations, and transmits them, via the tympanic membrane and the tiny bones (or Ossicles), into the inner ear, and Cochlea – which then converts the kinetic motion into electrical impulses to be transmitted to the brain… This is a very simplistic explanation for what is a quite complex set of interactions, and is explained in much more detail here. For our purposes, the other point to take note of along with the fact that our hearing apparatus is a very sensitive system is the action of the auditory canal (the bit that transmits sound from the outer ear onto the tympanic membrane). Because it acts essentially as a closed tube resonator, the auditory canal enhances sound in the range between 2 and 5KHz (which is, coincidentally, also the frequency range of the human voice). This rise in sensitivity is often referred to as the Fletcher/Munson curve (and is used extensively in perceptual compression techniques – ie MP3’s etc). It also causes what is referred to as the bass loss problem – essentially, though all frequencies drop off according to the inverse square law, our hearing makes the drop off of bass frequencies much more pronounced (and means therefore that the bass frequencies need more reinforcement than those in the Fletcher/Munson curve)…
Methods of measuring audio levels.
As you will (hopefully) be aware from the above information, although audio follows measurable physical laws, there is also a lot that is down to subjective interpretation – the size and shape of the ear and auditory canal dictate where maximum sensitivity lies for a particular person (and because we are all different, there is a good deal of variation in these values). The efficiency of all parts of the ear in amplifying the pressure wave and transmitting it to the Cochlea creates variation in perception of overall loudness, and the efficiency of the Cochlea in converting kinetic energy into electrical creates yet more variation…. The question is – how do we create a set of measurements on which we can all agree, and which gives some objective basis of comparison for sound levels? This is an essential question if we hope to have any scientific basis from which to begin engineering our sound reinforcement. It has been answered in a number of ways – none of which are entirely satisfactory, but each of which arrives at some sort of consensus for use as an objective base…. They are:
1) Sound Pressure.
This is the most basic measurement, and also the most objective – it is a measurement of the sound pressure (obviously) at a given point and time in comparison to atmospheric pressure, stated in newtons/m². It is of relatively limited use, because although it is a direct measurement of the pressure wave, it is a limited snapshot at a given time – to be useful we need a measurement of these snapshots over time, or an average level.
2) Sound Intensity.
This is the sound power per unit area, the usual context being a measurement of the average intensity at a given point. It is measured in Watts/m², or acoustic watts. Unlike the sound pressure measurement, this is a measurement of the sound energy at a given point as an average over time.
From this point, we need to relate the subjective sensation of loudness to some objective base. The way this is achieved is by the use of the Decibel scale or dB (named after Alexander Graham Bell – it equals 1/10th of a Bell). The basic premise is – when a sound of intensity I falls on the ear, what change ?I will cause the hearer to report a barely audible change in the sensation of loudness. Our hearing turns out to be so constructed that ?I is proportional to I – that is the more intense the sound, the greater ?I must be. So:
3) The Decibel scale, or dB.
Is a logarithmic scale used to measure loudness relative to a baseline known as the threshold of hearing. The threshold of hearing is an intensity of 10?¹²W/m² – chosen because it is near the lower limit of human audibility. The expression of loudness is then obtained by I(dB)=10log(¹º)[I/Iº], where I=the intensity, and Iº=the threshold of hearing. For an in depth analysis of this calculation, and how it is used, see this page. This scale is a useful measure of loudness, and is the standard measurement used in audio. It is not perfect however, as the human ear’s perception of loudness changes based on frequency (due to the effect of the auditory canal). The dB scale can be altered by use of contour filters (which effectively filter out frequencies that the ear does not hear well in order to more effectively simulate human hearing). Most common of these is the:
4) dBA – dB of sound with an “A” contour filter.
This the most commonly used contour filter, as it most closely mimics the hearing curve of the human ear. See here for a description of how it works – it is the scale generally used to measure the loudness at venues etc, or to measure ambient sound on a site etc.
These are the basic and most common measurements; there are others, either using different contour filters, or more closely relating the loudness by plotting equal loudness curves for the human ear, and then relating a dB value at a set frequency as in the Phon and Sone scales.
5) SPL, or Sound Pressure Level.
This is a measurement commonly used in the specs for speaker drivers, as one axis of a frequency response graph. Basically, the SPL is measured in dB when the speaker or system is fed 1Watt of electrical power, by placing a microphone 1m away – hence the curves shown on driver specs which show the output at varying frequency in dB SPL at 1w/1m. It is useful as a rough guide only, and shouldn’t be used as a guide to speaker driver quality (if you check such ratings, you will notice that mid range and tweeters invariably have higher dB ratings than woofers).
So, that is the basic physics/biology of audio – obviously there is a lot more, but hopefully this information should give you a sound basis. Again, I can recommend to you the Hyperphysics site which contains a huge amount of the theoretical information on sound, along with many of the engineering practices generally used.
For our purposes, and in conclusion we can reiterate the points that are going to be of most use to us in building our rig:
Audio is transmitted through air as a longitudinal wave, and follows the Inverse square law of physics. This logarithmic drop off in sound intensity is what we need to engineer to compensate for.
Our perception mechanism for sound is most sensitive in the human vocal range of 2-5KHz, and shows a marked drop off at the bass frequency range – we therefore need to reinforce these frequencies to compensate.
There are many ways of measuring audio, none of which are entirely satisfactory. The ones we will mostly be using however are: Intensity, measured in Acoustic watts (W/m²). Loudness, measured in dB, and ambient loudness measured using a contour filter (in dBA).
In the next section, we will investigate how audio is created or manipulated for the purpose of amplification.
November 2, 2007 at 7:42 am #1124058Basic Audio Theory:
This second section will investigate methods of creating/manipulating audio for the purpose of amplification.
Audio sources – string, reed, percussive, brass, voice and synthetic.
We create and manipulate audio in various ways, but all have the common goal of creating audio waves that are pleasing to listen to (the subjective nature of pleasure, and dissonance / consonance is another subject entirely, and not one I am going to discuss here. What we define as pleasure notwithstanding, pleasure is the common goal of music in all it’s forms.) Over the centuries, we have devised ever more complex and intricate methods of creating this audio, and manipulating the physical world to transmit it. It is generally accepted that the first instrument used for creating sound was percussive in nature, so we will start here:
The drum.
This category, which basically includes any instrument of a percussive nature (from 2 sticks banged together all the way to a full orchestral percussion section) work by using the elastic properties of a solid to set up a transverse waveform. This is usually accomplished by hitting with another solid (usually a drumstick of some form). The resulting deformation of the surface causes a transverse “ripple” to radiate from the point of impact, the result of which is a longitudinal pressure variation in the air perpendicular to the surface (a sound wave). The tonal characteristics etc are altered by the nature of the materials used, wether they are fixed at the ends/edges (as with a drum), or free (as in a Glockenspiel), and a number of other factors which are discussed here. As with most physical laws, they are essentially quite straightforward when taken singly, but become very complex very quickly when interacting (which is one of the reasons they are so difficult to synthesize properly – something we will touch on later). This use of a transverse deformation of a solid to create a longitudinal pressure variation is the basis for pretty much all acoustic sound though.
String, Voice and Brass.
I am putting these three methods into one section because they create sound waves in very similar ways (the minor differences in the method of creation of the sound are added to the differences in resonation chambers etc to produce very different tonal characteristics, but the original creation of the sound waves is very similar). Basically they take a solid vibrator that is fixed at both ends, and cause it to produce transverse waves over it’s length. With string instruments, it is a taught string, the tone varied by the taughtness and length of the string. In the human voice, the twin infoldings of mucous membrane at the base of the larynx, known as the vocal folds, or “vocal chords” do the job, the tone produced varied by the tension created by the muscles on either side. With brass instruments, the vibration is caused by air passing through the lips of the player, the tone varied by the tension of the lips. These similar beginnings then have sound added, taken away, distorted etc by various methods (from the interaction of waves reflecting at both fixed ends, to the properties of the various resonating chambers used, to the differences inherent in the materials causing the sound) to produce vastly different sounds. So much so that you would hardly credit a guitar and a trumpet with having anything in common other than that both make a noise – but as noted earlier, the physical laws – essentially straightforward when taken singly become very complex very quickly, and are capable of creating huge variation from similar beginnings.
Reed, or Woodwind.
Quite similar to the method of creating sound waves used by String, Voice and Brass, the main difference (in initial creation of the wave) in a “reed” type instrument is that the vibrating membrane is only fixed at one end, and therefore has different properties to one fixed at both ends. Note that although instruments like the Flute do not have reeds as such, the vibration for the sound is initiated by what is referred to as edge tone, and the mechanism is similar to that of a reed.
With all these methods, the variations in characteristics which make one so totally different to the others begin with the interactions that the incident and reflected transverse waves cause with each other, and are then modified by a varied set of resonating chambers etc to produce huge variation in the produced characteristics. My purpose in indicating the similarities is not to claim all instruments sound the same (far from it), but to point out that the huge variations are created from a similar source – a fact that is important both to the understanding of synthesized sound, and to the effective amplification of sound. The action of sounding boards, resonant chambers, resonating tubes and horns will be discussed further in section C.
Electrically amplified sound, and Synthetic sound.
While electrically amplified sound is not a sound source in itself, a very basic understanding of it is necessary for the understanding of Synthetic or Synthesized sound (we will go into it in detail in later sections). For the purposes of understanding synthesized sound, you need to understand how audio is transmitted electronically. The basic form uses a diaphragm to drive a piston, at the end of which is a material that exhibits Piezoelectric characteristics, thus converting the kinetic motion of the sound into an electrical representation of the same wave.
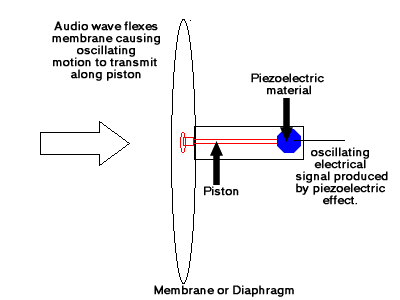
This representation (or analogue) of the sound can then be transmitted and amplified electronically before being converted back to kinetic energy (the sound wave) through the use of a speaker driver of some sort. The audio wave information is not actually altered, but the form of energy used for transmission is changed (which is why it is referred to as an analogue of the sound – the signal is not comparable, but the information is represented by a continuously variable quantity which can be measured and therefore converted back). The important fact is that it needs to be converted to kinetic energy to be heard – you cannot hear an electrical signal.
This ability to “encode” audio in electrical impulses, and then convert back to kinetic audio led to the invention of Synthesis – basically the creation of an oscillation in the electrical domain, which can then be manipulated by interacting with other oscillations, filtered, amplified and generally played with to create unique sounds unobtainable by normal acoustic means. There are many methods of synthesis, but all are based on causing these electrical impulses to interact in some way. It is interesting to note that while it is impossible to recreate some of the sounds of a synthesizer by acoustic means, it is also impossible (or at least extremly difficult) to recreate an acoustic instrument in any satisfactory way by synthesized means – the most effective method employed to date has been to record the sounds made by the instrument, and then play them back (hardly really “synthesis” as such). Actually creating from scratch something that even resembles the acoustic instrument requires an enormous amount of processing power to even come close (and even then, the results are not particularly satisfactory, and tend towards sounding “contrived”). The reasons for this, apart from the aforementioned complexity caused by the interactions of the waves in the oscillating membrane (be it drum skin, vocal chord, reed, string or lips) stem from the action of the resonator used to amplify/alter the sound, and are discussed in the next section.
Acoustic amplification – the soundboard, and various forms of resonant chambers, tubes and horns.
The property of Resonance is one that is fundamental to audio, and is the main cause of the huge variation in characteristics of acoustic instruments. The basic premise is that an object has a frequency at which it is easy to excite vibration, determined by the physical parameters of the object, and known as the resonant frequency. Most objects will usually have several resonant frequencies, and any complex excitation will cause it to vibrate at those frequencies, thereby effectively filtering out the non-resonant frequencies (the non-resonant frequencies are hard to excite by comparison, and so die away quickly from the original complex excitation, while the resonant ones sustain easily).
A pendulum is an example of an oscillation with a single frequency of resonance – it is easy to increase the amplitude of the oscillation if you time pushing the pendulum properly, but very difficult outside that timing – that timing is the resonant frequency (which can be changed by lengthening or shortening the length of the pendulum).
Most audio sources have multiple resonant frequencies (a fundamental, which is the main tone, and then several “harmonics” which are integer multiples of the fundamental). These harmonic resonances are formed by the action of standing waves – a characteristic pattern of resonance common to both string vibration, and air columns in which the combination of reflection and interference of the reflected waves with the incident waves cause the formation of “nodes” – ie reinforce each other to increase the overall amplitude at a particular frequency. In a string, the reflected vibration is flipped 180° in phase on reflection from a fixed end causing the string to appear to vibrate in segments – the fact that the vibration is made up of travelling waves is not apparent, hence the term “standing wave”. For an air column, the phase is only flipped at an open end (due to the energy loss associated with encountering a lesser acoustic impedance). The closed end does not cause a phase change because the wave is encountering a greater acoustic impedance.
For an in depth description of all the various permutations involved in the property of resonance, go here. For our purposes, the main information you need to remember is that we can use resonance as a sort of natural amplifier by using the properties of chambers, construction materials etc. We can also mitigate some of the effects of resonance – which is particularly useful in speaker enclosure design where we need to spread the resonant curve of the driver to flatten out the peak associated with the free air resonance of the cone. This produces an uneven response at a particular frequency, and thus a less accurate conversion of the signal (we call the inaccuracy distortion, as it is a distortion of the original sound). We will come back to some of the specifics later, but reading the information at Hyperphysics is highly recommended, as resonance is a fundamental concept in audio amplification. A basic understanding will probably do, but a good understanding of the principles will help you understand many of the other concepts far more easily. If you plan to engineer any kind of band, it will also give you some understanding of the best ways to fit particular instruments into your sound spectrum (by allowing you to understand the sound produced and how it’s overtones combine to create an instrument’s sound signature – and thus which frequencies can be used in other places, and which are essential to the character of the instrument) – essential to creating a clear, good mix, in which all the instruments sit properly.
There are some terms associated with resonance that bear explanation, as they are not necessarily obvious in their definition –
For harmonics the resonant frequencies are integer multiples of the fundamental (ie whole number multiples of the fundamental frequency in Hertz – referred to as 1st harmonic, 2nd harmonic etc) – but we can also have non harmonic resonant frequencies (percussive membranes particularly exhibit this characteristic), where they are not integer multiples. For this, the term overtone becomes useful:
We use the term “overtone” to indicate a resonant frequency above the fundamental, so in a string resonance, or open air column resonance, because they exhibit the characteristic of all harmonics being resonant frequencies we say they have harmonic overtones. Closed air columns also produce only harmonic overtones (although only the odd harmonic values), and are also said to have harmonic overtones. A drum however, will have non harmonic overtones along with some harmonic and so are said to have non-harmonic overtones.Audio Electronics 101 – Reproduction in analogue form.
The dictionary definition of analogue (the adjective) is:
1. (not comparable) (Of a device or system) in which the value of a data item (such as time) is represented by a continuously variable physical quantity that can be measured (such as the shadow of a sundial)
We already touched on the basics of creating an “analogue” of a sound in electrical form, so this section will be relatively brief. The basic concept of taking a kinetic input – which can be a raw sound wave (the example we used), or an oscillation produced by an instrument or device, and converting it into electrical impulses was the historical beginning of both PA reinforcement, and the recording of audio for later playback. The idea of creating an analogue of the audio wave using a different energy form to represent the original really began with the phonograph (from the greek root phono – meaning “sound”, and graph – meaning “writer”) – a device which encoded the representation of the sound wave onto a physical surface (in the form of a disc, or drum), by using a long track, or groove to represent time, and the indentations made in the groove to represent amplitude (there are various claims for who invented the first phonograph, but Thomas Edison seems to have the honour of patenting the first system that could replay the information as well as encode it).
This basis of using an analogue of a sound wave to record onto a physical medium is the basis of all sound recording techniques, and we can trace it’s origin right back to the wind up organs of the renaissance (which used indentations in a drum to play a tune on a set of tuned metal strips). The use of electrical impulses to represent the sound wave is obviously later, and is the basis for all reinforcement techniques that aren’t based around the configuration of venue acoustics (reinforcement of sound has a history stretching right back to ancient Greece, and the semicircular Theatre designs like the Dionysus Theatre in Athens. The culmination of knowledge in this area has resulted in designs like the Sydney opera house, and the Palau de la Musica in Barcelona amongst others – and the science of auditorium acoustics is as vital to an engineer as the science of amplification…)
The use of electricity as a medium for encoding the data required for an analogue representation allowed the use of further conversions (from electrical to magnetic for instance, as in the case of magnetic tape), and also allowed the encoding into higher frequency spectra, as in the case of radio waves which could then be transmitted over vast distances to be decoded back into the original sound.
Various techniques were also discovered to encode more information into the various analogue representations – the first devices were mono in operation, but stereo representations were invented, and quickly became the standard (humans have 2 ears, so stereo was a natural progression). These basically encode the audio into the groove walls – one on either side, using the lateral motion as well as the vertical motion to encode the electrical signals. The pickup and tonearm design then effectively “decode” the movement and convert it back to stereo audio.
This is one of the main characteristics of analogue devices – there is no real “encoding” as such of the sound data – the waveform is actually created as an exact copy, and only requires energy conversion to reproduce the original. This has several advantages in terms of fidelity, but one main drawback. The analogue representation cannot be compressed without losing information. That isn’t to say you can’t compress it (AM, and FW radio compresses the analogue wave considerably before transmission), but doing so produces instantly noticeable changes in the reproduced wave at the other end.
This idea for using a representation of the sound in a different medium led to the invention of digital encoding however:
Audio electronics 01100101 – Reproduction in digital form.
With the invention of computing, came the idea that you could store a representation of a sound in digital form. The basic premise takes the analogue electrical representation (which is essentially a function of amplitude over time), and samples it at a constant rate (known as the sampling rate). Each sample is then represented as a binary numerical value with polarity encoded using the two’s complement system. The bit depth is therefore the precision of the numerical values representing each sample (8 bit encoding gets you 128 positive or negative values – essentially 256 unique values. 16 bit encoding gets you 32768 +ve or -ve values essentially 65536 unique values). Obviously, the higher the bit depth, the more precise the encoding available (this is referred to as the resolution) , and the higher the sample rate, the more frequencies can be represented. This relationship of sample rate to frequency is described in Nyquist’s sampling theorem: The sampling rate must equal double the highest frequency component, or turned around, the highest frequency encodable in a digital representation is equal to 1/2 the sample rate. The full glory of Nyquist et al’s theorem (which has a collection of names, but is most easily known as The sampling theorem) can be found here on Wikipedia if you want to treat yourself to a maths overdose.
The amount of information encodable (in terms of stereo/surround etc) is limited only by the processing speed of the equipment, a fact that is responsible for the relatively low sample rate and bit depth of standard audio CD’s (when they were invented, the roughly 1.4MHz of processing power needed to process 44,100 samples per second at 16 bit in stereo was the cutting edge of computer technology. Now of course, it’s a tiny amount, but the standard has been set and has been used for many years). The small amount of loss (most people can’t hear it at all) in the encoding is acceptable given the convenience of the standard, and the difficulties in changing it…. As an engineer however, I would recommend using the best sample rate/bit depth combination you can manage – especially for recording anything, as some people hear loss of the above 22,050Hz information not encoded on CD’s (and it is possible that other people, while they cannot hear it as such do perceive it somehow – many people describe CD’s as clinical, or cold sounding, and when played audio recorded at a higher rate prefer it). Remember, due to the subjective nature of much sound perception, the commonly used constant values are only a “best average” that we use for convenience – there are people with hearing perception outside these values…. As processing power is ample and cheap these days, you have nothing to lose by using higher rates and bit depths – the only sticking point to remember is that when downsampling (going from a high sample rate and bit depth to a lower one), you need to use an anti aliasing filter as described in the sampling theorem – I am not going to go into the whys and wherefore’s here (partly because I don’t fully understand them myself) – the info on the Wikipedia site is accurate AFAIK, and quite comprehensive if the subject fascinates you…
The pertinent facts for our purposes are the limits described by the Nyquist rate (sample rate=2xhighest frequency encodable), and the fact that you need to anti-alias when you downsample (upsampling while possible is not ideal – once the information is lost, replacing it can only be done by some form of interpolation – a guess at best). If you start at the high rate and resolution, you lose nothing in downsampling, but (especially if you oversample), the extra information encoded can be useful when compression is applied (eg when you encode to MP3, Ogg) as lossy compression techniques particularly benefit from the extra information:
Audio electronics 0065 – Compressing by various means.
The process of digitising our audio representation also opens up the doorway to the use of compression techniques – which allow us to represent the sound in a smaller package (useful for storage, transmission electronically using the likes of the internet, and allowing large amounts of audio data to be squeezed into ever tinier devices)….
There are two methods of compressing data; lossless, and lossy. As the names suggest, lossless compression doesn’t lose any of the information, whereas lossy does.
Lossless compression is difficult in audio, because the information changes rapidly, and constantly – therefore standard algorithms don’t work very well. However, convolution with a [-1 1] filter tends to whiten, or flatten the spectrum slightly, thereby allowing the use of traditional techniques like Huffman Run length encoding (HRLE), Lempel-Ziv-Welch (LZW) etc. Integration at the decoder then restores the original signal. Various CODECS (COder/DECoders) use Linear Prediction Coding (LPC) techniques to estimate the spectrum of the signal. An inverse of the estimator (which is a statistical method of prediction using Maximum Likelihood Estimation (MLE) to fit real world data into a mathematical model in an optimum way) is used to whiten the spectral peaks, while the estimator is used to reconstruct the original signal at the decoder.
There are many different loseless CODECS available, and a comparison of the pros and cons can be found here.
Lossy compression techniques have been very prevalent until recent years, due to the high rate of compression they can achieve – the small packages enabled transmission over the relatively slow internet, and the fitting of lots of audio into the relatively small size storage devices of the time. They are losing popularity slowly, due to the speeding up of network transmission, and the miniturisation of comparatively large storage media (20GB of data storage for a media player enables the storage of over 2000 minutes of uncompressed CD quality audio, or over 33 hours and 20mins). Lossless compression is able to almost double this – so you get the idea (I defy anybody to need 60+ hours of audio storage for entertainment)…
Lossy techniques do have applications where they are still essential though (radio streaming over the internet for example, which needs a low bitrate to allow as many connections as possible).
Of the lossy algorithms, MP3 is the best known, with newer algorithms like Ogg Vorbis, Apple’s AAC, and Sony’s ATRAC being also widely used (although less well known). These lossy techniques primarily use what is known as Psychoacoustics to discard information that (hopefully) the loss of will not affect the perception of the audio. So, for example, because the human ear has a higher sensitivity to the 2-5KHz frequency band as discussed in the biology section, we can discard some of the data above and below those frequencies. Or due to what is called the “masking effect”, where a loud sound masks a quiter one making it inaudible, we can lose some of the data for the quiter sound. I am not going to investigate the methods in depth, as Wikipedia again has an excellent article.
To achieve these perception based encodings, various methods are used – from transform domain methods, whereby the sound has a discrete transform applied to it (our lossless convolution technique begins with a Discrete Transform known as a Discrete Fourier Transform (DFT)). A related transform known as a Modified Discrete Cosine Transform (MDCT) is used in encoding MP3’s – not on the audio signal directly, but rather on the output of a 32 band Polyphase Quadrature Filter (PQF) bank. The output of this MDCT is then used in an alias reduction technique to reduce the typical aliasing of a PQF bank at each band.
Time domain coding (like the LPC used in lossless compression) can be used with models of the sound’s generator as the estimation technique to create much higher compression than our previous use of an inverse convoluted estimator for lossless compression. These models cause loss of the data because they use a set model estimation, rather than a comparison estimation (an example would be using a model of the human vocal tract to whiten the spectrum when encoding speech)…
As should (hopefully) be obvious by now, the fidelity of reproduction when using lossy compression is highly dependent on both the quantity of compression applied, and the depth of analysis applied during encoding. The quantity applied dictates how severe the dropping of “inaudible” frequencies etc will be, while the depth of analysis during encoding dictates how accurate the predictive model will be. As processing power has multiplied, the accuracy of the model has increased (which is the reason newer methods like Ogg, and AAC are better at lower bitrates than older formats like MP3 – the original design of which was created almost 20 years ago)…
So as an engineer, your preference should start with as high a bitrate representation as possible, and be lowered only by absolutely necessary conditions (ie target medium, or bandwidth restrictions etc). You can always “lose” information, but once lost, it is difficult, if not impossible to get back….
This has been a fairly whirlwind investigation of audio representation techniques which I hope has made some useful sense. Don’t worry if you don’t understand it all (if you do, then please correct any mistakes I have made, as I get lost on some of it – especially the maths which has never been a favourite subject of mine). The idea is to develop an overview of how it works, and to understand the pertinent facts which relate to the practical aspects we will be investigating later on…..
November 2, 2007 at 7:42 am #1144976Basic Audio Theory:
This second section will investigate methods of creating/manipulating audio for the purpose of amplification.
Audio sources – string, reed, percussive, brass, voice and synthetic.
We create and manipulate audio in various ways, but all have the common goal of creating audio waves that are pleasing to listen to (the subjective nature of pleasure, and dissonance / consonance is another subject entirely, and not one I am going to discuss here. What we define as pleasure notwithstanding, pleasure is the common goal of music in all it’s forms.) Over the centuries, we have devised ever more complex and intricate methods of creating this audio, and manipulating the physical world to transmit it. It is generally accepted that the first instrument used for creating sound was percussive in nature, so we will start here:
The drum.
This category, which basically includes any instrument of a percussive nature (from 2 sticks banged together all the way to a full orchestral percussion section) work by using the elastic properties of a solid to set up a transverse waveform. This is usually accomplished by hitting with another solid (usually a drumstick of some form). The resulting deformation of the surface causes a transverse “ripple” to radiate from the point of impact, the result of which is a longitudinal pressure variation in the air perpendicular to the surface (a sound wave). The tonal characteristics etc are altered by the nature of the materials used, wether they are fixed at the ends/edges (as with a drum), or free (as in a Glockenspiel), and a number of other factors which are discussed here. As with most physical laws, they are essentially quite straightforward when taken singly, but become very complex very quickly when interacting (which is one of the reasons they are so difficult to synthesize properly – something we will touch on later). This use of a transverse deformation of a solid to create a longitudinal pressure variation is the basis for pretty much all acoustic sound though.
String, Voice and Brass.
I am putting these three methods into one section because they create sound waves in very similar ways (the minor differences in the method of creation of the sound are added to the differences in resonation chambers etc to produce very different tonal characteristics, but the original creation of the sound waves is very similar). Basically they take a solid vibrator that is fixed at both ends, and cause it to produce transverse waves over it’s length. With string instruments, it is a taught string, the tone varied by the taughtness and length of the string. In the human voice, the twin infoldings of mucous membrane at the base of the larynx, known as the vocal folds, or “vocal chords” do the job, the tone produced varied by the tension created by the muscles on either side. With brass instruments, the vibration is caused by air passing through the lips of the player, the tone varied by the tension of the lips. These similar beginnings then have sound added, taken away, distorted etc by various methods (from the interaction of waves reflecting at both fixed ends, to the properties of the various resonating chambers used, to the differences inherent in the materials causing the sound) to produce vastly different sounds. So much so that you would hardly credit a guitar and a trumpet with having anything in common other than that both make a noise – but as noted earlier, the physical laws – essentially straightforward when taken singly become very complex very quickly, and are capable of creating huge variation from similar beginnings.
Reed, or Woodwind.
Quite similar to the method of creating sound waves used by String, Voice and Brass, the main difference (in initial creation of the wave) in a “reed” type instrument is that the vibrating membrane is only fixed at one end, and therefore has different properties to one fixed at both ends. Note that although instruments like the Flute do not have reeds as such, the vibration for the sound is initiated by what is referred to as edge tone, and the mechanism is similar to that of a reed.
With all these methods, the variations in characteristics which make one so totally different to the others begin with the interactions that the incident and reflected transverse waves cause with each other, and are then modified by a varied set of resonating chambers etc to produce huge variation in the produced characteristics. My purpose in indicating the similarities is not to claim all instruments sound the same (far from it), but to point out that the huge variations are created from a similar source – a fact that is important both to the understanding of synthesized sound, and to the effective amplification of sound. The action of sounding boards, resonant chambers, resonating tubes and horns will be discussed further in section C.
Electrically amplified sound, and Synthetic sound.
While electrically amplified sound is not a sound source in itself, a very basic understanding of it is necessary for the understanding of Synthetic or Synthesized sound (we will go into it in detail in later sections). For the purposes of understanding synthesized sound, you need to understand how audio is transmitted electronically. The basic form uses a diaphragm to drive a piston, at the end of which is a material that exhibits Piezoelectric characteristics, thus converting the kinetic motion of the sound into an electrical representation of the same wave.
This representation (or analogue) of the sound can then be transmitted and amplified electronically before being converted back to kinetic energy (the sound wave) through the use of a speaker driver of some sort. The audio wave information is not actually altered, but the form of energy used for transmission is changed (which is why it is referred to as an analogue of the sound – the signal is not comparable, but the information is represented by a continuously variable quantity which can be measured and therefore converted back). The important fact is that it needs to be converted to kinetic energy to be heard – you cannot hear an electrical signal.
This ability to “encode” audio in electrical impulses, and then convert back to kinetic audio led to the invention of Synthesis – basically the creation of an oscillation in the electrical domain, which can then be manipulated by interacting with other oscillations, filtered, amplified and generally played with to create unique sounds unobtainable by normal acoustic means. There are many methods of synthesis, but all are based on causing these electrical impulses to interact in some way. It is interesting to note that while it is impossible to recreate some of the sounds of a synthesizer by acoustic means, it is also impossible (or at least extremly difficult) to recreate an acoustic instrument in any satisfactory way by synthesized means – the most effective method employed to date has been to record the sounds made by the instrument, and then play them back (hardly really “synthesis” as such). Actually creating from scratch something that even resembles the acoustic instrument requires an enormous amount of processing power to even come close (and even then, the results are not particularly satisfactory, and tend towards sounding “contrived”). The reasons for this, apart from the aforementioned complexity caused by the interactions of the waves in the oscillating membrane (be it drum skin, vocal chord, reed, string or lips) stem from the action of the resonator used to amplify/alter the sound, and are discussed in the next section.
Acoustic amplification – the soundboard, and various forms of resonant chambers, tubes and horns.
The property of Resonance is one that is fundamental to audio, and is the main cause of the huge variation in characteristics of acoustic instruments. The basic premise is that an object has a frequency at which it is easy to excite vibration, determined by the physical parameters of the object, and known as the resonant frequency. Most objects will usually have several resonant frequencies, and any complex excitation will cause it to vibrate at those frequencies, thereby effectively filtering out the non-resonant frequencies (the non-resonant frequencies are hard to excite by comparison, and so die away quickly from the original complex excitation, while the resonant ones sustain easily).
A pendulum is an example of an oscillation with a single frequency of resonance – it is easy to increase the amplitude of the oscillation if you time pushing the pendulum properly, but very difficult outside that timing – that timing is the resonant frequency (which can be changed by lengthening or shortening the length of the pendulum).
Most audio sources have multiple resonant frequencies (a fundamental, which is the main tone, and then several “harmonics” which are integer multiples of the fundamental). These harmonic resonances are formed by the action of standing waves – a characteristic pattern of resonance common to both string vibration, and air columns in which the combination of reflection and interference of the reflected waves with the incident waves cause the formation of “nodes” – ie reinforce each other to increase the overall amplitude at a particular frequency. In a string, the reflected vibration is flipped 180° in phase on reflection from a fixed end causing the string to appear to vibrate in segments – the fact that the vibration is made up of travelling waves is not apparent, hence the term “standing wave”. For an air column, the phase is only flipped at an open end (due to the energy loss associated with encountering a lesser acoustic impedance). The closed end does not cause a phase change because the wave is encountering a greater acoustic impedance.
For an in depth description of all the various permutations involved in the property of resonance, go here. For our purposes, the main information you need to remember is that we can use resonance as a sort of natural amplifier by using the properties of chambers, construction materials etc. We can also mitigate some of the effects of resonance – which is particularly useful in speaker enclosure design where we need to spread the resonant curve of the driver to flatten out the peak associated with the free air resonance of the cone. This produces an uneven response at a particular frequency, and thus a less accurate conversion of the signal (we call the inaccuracy distortion, as it is a distortion of the original sound). We will come back to some of the specifics later, but reading the information at Hyperphysics is highly recommended, as resonance is a fundamental concept in audio amplification. A basic understanding will probably do, but a good understanding of the principles will help you understand many of the other concepts far more easily. If you plan to engineer any kind of band, it will also give you some understanding of the best ways to fit particular instruments into your sound spectrum (by allowing you to understand the sound produced and how it’s overtones combine to create an instrument’s sound signature – and thus which frequencies can be used in other places, and which are essential to the character of the instrument) – essential to creating a clear, good mix, in which all the instruments sit properly.
There are some terms associated with resonance that bear explanation, as they are not necessarily obvious in their definition –
For harmonics the resonant frequencies are integer multiples of the fundamental (ie whole number multiples of the fundamental frequency in Hertz – referred to as 1st harmonic, 2nd harmonic etc) – but we can also have non harmonic resonant frequencies (percussive membranes particularly exhibit this characteristic), where they are not integer multiples. For this, the term overtone becomes useful:
We use the term “overtone” to indicate a resonant frequency above the fundamental, so in a string resonance, or open air column resonance, because they exhibit the characteristic of all harmonics being resonant frequencies we say they have harmonic overtones. Closed air columns also produce only harmonic overtones (although only the odd harmonic values), and are also said to have harmonic overtones. A drum however, will have non harmonic overtones along with some harmonic and so are said to have non-harmonic overtones.Audio Electronics 101 – Reproduction in analogue form.
The dictionary definition of analogue (the adjective) is:
1. (not comparable) (Of a device or system) in which the value of a data item (such as time) is represented by a continuously variable physical quantity that can be measured (such as the shadow of a sundial)
We already touched on the basics of creating an “analogue” of a sound in electrical form, so this section will be relatively brief. The basic concept of taking a kinetic input – which can be a raw sound wave (the example we used), or an oscillation produced by an instrument or device, and converting it into electrical impulses was the historical beginning of both PA reinforcement, and the recording of audio for later playback. The idea of creating an analogue of the audio wave using a different energy form to represent the original really began with the phonograph (from the greek root phono – meaning “sound”, and graph – meaning “writer”) – a device which encoded the representation of the sound wave onto a physical surface (in the form of a disc, or drum), by using a long track, or groove to represent time, and the indentations made in the groove to represent amplitude (there are various claims for who invented the first phonograph, but Thomas Edison seems to have the honour of patenting the first system that could replay the information as well as encode it).
This basis of using an analogue of a sound wave to record onto a physical medium is the basis of all sound recording techniques, and we can trace it’s origin right back to the wind up organs of the renaissance (which used indentations in a drum to play a tune on a set of tuned metal strips). The use of electrical impulses to represent the sound wave is obviously later, and is the basis for all reinforcement techniques that aren’t based around the configuration of venue acoustics (reinforcement of sound has a history stretching right back to ancient Greece, and the semicircular Theatre designs like the Dionysus Theatre in Athens. The culmination of knowledge in this area has resulted in designs like the Sydney opera house, and the Palau de la Musica in Barcelona amongst others – and the science of auditorium acoustics is as vital to an engineer as the science of amplification…)
The use of electricity as a medium for encoding the data required for an analogue representation allowed the use of further conversions (from electrical to magnetic for instance, as in the case of magnetic tape), and also allowed the encoding into higher frequency spectra, as in the case of radio waves which could then be transmitted over vast distances to be decoded back into the original sound.
Various techniques were also discovered to encode more information into the various analogue representations – the first devices were mono in operation, but stereo representations were invented, and quickly became the standard (humans have 2 ears, so stereo was a natural progression). These basically encode the audio into the groove walls – one on either side, using the lateral motion as well as the vertical motion to encode the electrical signals. The pickup and tonearm design then effectively “decode” the movement and convert it back to stereo audio.
This is one of the main characteristics of analogue devices – there is no real “encoding” as such of the sound data – the waveform is actually created as an exact copy, and only requires energy conversion to reproduce the original. This has several advantages in terms of fidelity, but one main drawback. The analogue representation cannot be compressed without losing information. That isn’t to say you can’t compress it (AM, and FW radio compresses the analogue wave considerably before transmission), but doing so produces instantly noticeable changes in the reproduced wave at the other end.
This idea for using a representation of the sound in a different medium led to the invention of digital encoding however:
Audio electronics 01100101 – Reproduction in digital form.
With the invention of computing, came the idea that you could store a representation of a sound in digital form. The basic premise takes the analogue electrical representation (which is essentially a function of amplitude over time), and samples it at a constant rate (known as the sampling rate). Each sample is then represented as a binary numerical value with polarity encoded using the two’s complement system. The bit depth is therefore the precision of the numerical values representing each sample (8 bit encoding gets you 128 positive or negative values – essentially 256 unique values. 16 bit encoding gets you 32768 +ve or -ve values essentially 65536 unique values). Obviously, the higher the bit depth, the more precise the encoding available (this is referred to as the resolution) , and the higher the sample rate, the more frequencies can be represented. This relationship of sample rate to frequency is described in Nyquist’s sampling theorem: The sampling rate must equal double the highest frequency component, or turned around, the highest frequency encodable in a digital representation is equal to 1/2 the sample rate. The full glory of Nyquist et al’s theorem (which has a collection of names, but is most easily known as The sampling theorem) can be found here on Wikipedia if you want to treat yourself to a maths overdose.
The amount of information encodable (in terms of stereo/surround etc) is limited only by the processing speed of the equipment, a fact that is responsible for the relatively low sample rate and bit depth of standard audio CD’s (when they were invented, the roughly 1.4MHz of processing power needed to process 44,100 samples per second at 16 bit in stereo was the cutting edge of computer technology. Now of course, it’s a tiny amount, but the standard has been set and has been used for many years). The small amount of loss (most people can’t hear it at all) in the encoding is acceptable given the convenience of the standard, and the difficulties in changing it…. As an engineer however, I would recommend using the best sample rate/bit depth combination you can manage – especially for recording anything, as some people hear loss of the above 22,050Hz information not encoded on CD’s (and it is possible that other people, while they cannot hear it as such do perceive it somehow – many people describe CD’s as clinical, or cold sounding, and when played audio recorded at a higher rate prefer it). Remember, due to the subjective nature of much sound perception, the commonly used constant values are only a “best average” that we use for convenience – there are people with hearing perception outside these values…. As processing power is ample and cheap these days, you have nothing to lose by using higher rates and bit depths – the only sticking point to remember is that when downsampling (going from a high sample rate and bit depth to a lower one), you need to use an anti aliasing filter as described in the sampling theorem – I am not going to go into the whys and wherefore’s here (partly because I don’t fully understand them myself) – the info on the Wikipedia site is accurate AFAIK, and quite comprehensive if the subject fascinates you…
The pertinent facts for our purposes are the limits described by the Nyquist rate (sample rate=2xhighest frequency encodable), and the fact that you need to anti-alias when you downsample (upsampling while possible is not ideal – once the information is lost, replacing it can only be done by some form of interpolation – a guess at best). If you start at the high rate and resolution, you lose nothing in downsampling, but (especially if you oversample), the extra information encoded can be useful when compression is applied (eg when you encode to MP3, Ogg) as lossy compression techniques particularly benefit from the extra information:
Audio electronics 0065 – Compressing by various means.
The process of digitising our audio representation also opens up the doorway to the use of compression techniques – which allow us to represent the sound in a smaller package (useful for storage, transmission electronically using the likes of the internet, and allowing large amounts of audio data to be squeezed into ever tinier devices)….
There are two methods of compressing data; lossless, and lossy. As the names suggest, lossless compression doesn’t lose any of the information, whereas lossy does.
Lossless compression is difficult in audio, because the information changes rapidly, and constantly – therefore standard algorithms don’t work very well. However, convolution with a [-1 1] filter tends to whiten, or flatten the spectrum slightly, thereby allowing the use of traditional techniques like Huffman Run length encoding (HRLE), Lempel-Ziv-Welch (LZW) etc. Integration at the decoder then restores the original signal. Various CODECS (COder/DECoders) use Linear Prediction Coding (LPC) techniques to estimate the spectrum of the signal. An inverse of the estimator (which is a statistical method of prediction using Maximum Likelihood Estimation (MLE) to fit real world data into a mathematical model in an optimum way) is used to whiten the spectral peaks, while the estimator is used to reconstruct the original signal at the decoder.
There are many different loseless CODECS available, and a comparison of the pros and cons can be found here.
Lossy compression techniques have been very prevalent until recent years, due to the high rate of compression they can achieve – the small packages enabled transmission over the relatively slow internet, and the fitting of lots of audio into the relatively small size storage devices of the time. They are losing popularity slowly, due to the speeding up of network transmission, and the miniturisation of comparatively large storage media (20GB of data storage for a media player enables the storage of over 2000 minutes of uncompressed CD quality audio, or over 33 hours and 20mins). Lossless compression is able to almost double this – so you get the idea (I defy anybody to need 60+ hours of audio storage for entertainment)…
Lossy techniques do have applications where they are still essential though (radio streaming over the internet for example, which needs a low bitrate to allow as many connections as possible).
Of the lossy algorithms, MP3 is the best known, with newer algorithms like Ogg Vorbis, Apple’s AAC, and Sony’s ATRAC being also widely used (although less well known). These lossy techniques primarily use what is known as Psychoacoustics to discard information that (hopefully) the loss of will not affect the perception of the audio. So, for example, because the human ear has a higher sensitivity to the 2-5KHz frequency band as discussed in the biology section, we can discard some of the data above and below those frequencies. Or due to what is called the “masking effect”, where a loud sound masks a quiter one making it inaudible, we can lose some of the data for the quiter sound. I am not going to investigate the methods in depth, as Wikipedia again has an excellent article.
To achieve these perception based encodings, various methods are used – from transform domain methods, whereby the sound has a discrete transform applied to it (our lossless convolution technique begins with a Discrete Transform known as a Discrete Fourier Transform (DFT)). A related transform known as a Modified Discrete Cosine Transform (MDCT) is used in encoding MP3’s – not on the audio signal directly, but rather on the output of a 32 band Polyphase Quadrature Filter (PQF) bank. The output of this MDCT is then used in an alias reduction technique to reduce the typical aliasing of a PQF bank at each band.
Time domain coding (like the LPC used in lossless compression) can be used with models of the sound’s generator as the estimation technique to create much higher compression than our previous use of an inverse convoluted estimator for lossless compression. These models cause loss of the data because they use a set model estimation, rather than a comparison estimation (an example would be using a model of the human vocal tract to whiten the spectrum when encoding speech)…
As should (hopefully) be obvious by now, the fidelity of reproduction when using lossy compression is highly dependent on both the quantity of compression applied, and the depth of analysis applied during encoding. The quantity applied dictates how severe the dropping of “inaudible” frequencies etc will be, while the depth of analysis during encoding dictates how accurate the predictive model will be. As processing power has multiplied, the accuracy of the model has increased (which is the reason newer methods like Ogg, and AAC are better at lower bitrates than older formats like MP3 – the original design of which was created almost 20 years ago)…
So as an engineer, your preference should start with as high a bitrate representation as possible, and be lowered only by absolutely necessary conditions (ie target medium, or bandwidth restrictions etc). You can always “lose” information, but once lost, it is difficult, if not impossible to get back….
This has been a fairly whirlwind investigation of audio representation techniques which I hope has made some useful sense. Don’t worry if you don’t understand it all (if you do, then please correct any mistakes I have made, as I get lost on some of it – especially the maths which has never been a favourite subject of mine). The idea is to develop an overview of how it works, and to understand the pertinent facts which relate to the practical aspects we will be investigating later on…..
February 13, 2008 at 7:36 pm #1124066Basic Audio Theory
This third section is intended to be a basic introduction and discussion of the various pieces of equipment used in sound reinforcement
Audio Amplifiers
The amplifier is perhaps the most important (and certainly the most ubiquitous) piece of electronics in existence today. In fact, it could easily be argued that without the humble amplifier, most of the advances in electronics from the past 100 years would have been impossible. Equally, it is difficult to imagine a world without the various audio amplifiers that we are surrounded by in everyday life – from the amplifier in our hi-fi’s to the TV, PC, and mobile phone, amplifiers are all around us, and permeate our everyday existence. So what exactly are audio amplifiers?
To answer this question, look back to the previous sections of this how to, and re-imagine the analogue representation of our audio signal. Now, as can hopefully be seen from the previous examples, the linear representations of our audio signal (whether they come from a tiny moving coil as in a phonograph needle, or from a DA conversion circuit in a CD) are necessarily very small (for a standard line level, only 1 or 2 volts maximum, and only a few millivolts for a phono needle). If we are hoping to drive the huge coil/magnet combinations of the average speaker driver, they will obviously need to be far larger. The answer to this problem is the amplifier.
Here, it is worth noting the delineation between what engineers refer to as “signal” level voltages, and “line” level voltages. A signal level voltage is what we refer to when we are talking about the few millivolt signal commonly output by a phonograph, or a guitar pickup etc. These require what we call a “pre-amplifier” to bring them up to the common “line” level voltage (usually 500mV for consumer equipment, and 1-2V for pro equipment). A pre-amplifier is a voltage amplifier (it has no effect on current level) who’s sole purpose is to bring a signal level up to a line level (some pre-amps will also include various conditioning circuits depending on the device the pre-amp is designed for as well). In contrast, a power amplifier is designed to take a line level signal, and amplify it to a corresponding high voltage, and high current signal for the purpose of driving a low impedance speaker coil…
So how do we perform this particular piece of magic? With the help of the humble transistor (it can also be done with vacuum tubes, and many argue it is better done with these devices – the only answer I will give to this assertion is go and count how many recording studios have tube amplifiers fitted for their mastering setups…) The transistor (whether it be JFET, MOS-FET or BJT) is basically a device that can take an input signal at it’s gate (or base for bipolars), and use it essentially as a valve for a more powerful current (in bipolar types) or voltage (for FET’s) across its source-drain (or collector-emitter in bipolars) so producing a larger analogue of the base signal at it’s drain (or emitter). That is essentially an audio amplifier (at it’s most basic). This is an over-simplification, but the analogy should help in giving a working understanding of what the amplifier circuit actually does. Obviously there are many designs and varied ways of putting these transistors together, but I think I can probably say that 99% of designs for power amplifiers today follow the topology made by RCA in 1956 which is the 3 stage design:
1st stage: Usually referred to as the input stage, this is a transconductance (voltage to current) amplifier. It basically buffers the signal and amplifies it into a proportional current signal applied to the low impedance input of the second stage (these are pretty much always differential amplifiers as it allows the convenience of having an inverting input for negative feedback, and decent power supply rejection ratio characteristics).
2nd stage: The voltage amplifier stage (or VA stage). This is a transimpedance (current to voltage) amplifier. It receives the current signal from the input stage, and converts it to a high level voltage signal (and also provides the gain compensation that is critical to overall stability).
3rd stage: The output stage (or OPS). This is basically a current amplifier – it takes the high voltage signal from the VA stage, and amplifies the current to give a near unity voltage gain high current output to the speaker load. There are a variety of ways that this stage can be configured, but it is essentially a bi-directional common-collector amplifier.
Hopefully this has given some insight into what actually happens “under the hood” so to speak in a common power amplifier. If you want to learn more, and are interested in designing your own power amplifiers, I can highly recommend G. Randy Slone’s “High power audio amplifier construction manual”, which goes into this subject in far more depth, and includes practical examples up to a design for an 1100 watt power amp….
As a final note (and with the intent of keeping the reference info slightly separate from the general waffling 🙂 ), I thought I’d finish this section with a rundown of the typical characteristics a manufacturer will give for an amplifier, and what they mean…
Rated power A manufacturer will give a power rating (RMS) at various load impedances (usually 8ohm, 4ohm, and 2ohm). This is the output power measured using a 1KHz signal (generally – it will state if not) that the amplifier produces. This is the power rating that you should use to match your amplifier with your speaker load.
Rated power (bridge mode) Bridging is a way of getting much larger output from an amplifier by taking a stereo amplifier, having one side 180 degrees out of phase with the other, and then connecting the speaker across the high sides (ie the output rails) of each amplifier. A spec sheet will generally give a bridged output rating at 8 and 4 ohm.
Minimum load impedance The minimum impedance of the total speaker load connected to the amplifier (many amps have a minimum load impedance of 2ohm, but I personally tend to avoid using an output load this low for various reasons from inherent large signal nonlinearity in 2 ohm loads to the fact that at a 2ohm load, the components are going to be at the very limit of their thermal cyclic curves which is never good for them. For practical application, I would recommend not going below a 4ohm load, but you pays your money, you takes your choice… 😉 )
Frequency response The frequencies at which the amplifier will provide amplification. For all practical purposes in any amplifier, this will cover the audible range and then some (10Hz-100KHz is from below what you can hear to way way above…)
THD, or Total Harmonic Distortion Expressed as a percentage value, this is the amount of harmonic distortion (ie unwanted additions to the signal) that the amplifier produces. This will typically be around 0.2% for modern solid state amps, and can pretty much be ignored as a spec (Your speaker system will produce far far more distortion than any amplifier in production, and I would defy anybody to pick out a 0.1%THD amp from a 0.2%THD amp in a blind test…) Obviously lower THD is better, but for practical purposes, don’t worry about it too much…
CMRR, or Common Mode Rejection Ratio The ability of the amplifier to filter out “common mode” signals within it’s signal path (common mode signals tend to be EMI, or distortion introduced in the signal path). Usually expressed as a ratio at 1KHz (ie – 55dB would be 55:1). Generally bigger is better.
Slew rate This is the maximum rate of voltage change at the output of the amplifier, and is probably the best indicator of the amplifiers speed (it is usually given in Volts/microsecond). This is obviously important from the point of view of frequency response and signal linearity (if the amplifier can’t follow the signal quickly enough, there will be distortion introduced into the signal), and it would seem that faster is better. This holds true for the most part, but can be taken to ridiculous and possibly detrimental extremes (in which the high frequency instability introduced by an excessively high slew rate outweighs the supposed benefits gained). I’m not going to go into the whole gory detail here however, as for the most part any amplifier available commercially will have an acceptable slew rate for it’s power rating…
Damping factor The ratio of the output stage impedance and the speaker system impedance. The ideal amplifier would be a perfect voltage source to the speaker being driven by it. In the real world however, this doesn’t happen, but we try and get this ratio as high as possible (so the load variation has as little effect on the output voltage as possible). There’s a lot of general waffle on this subject, but my advice is to not worry about it too much…
There are sometimes other specs given for amplifiers, but these are the most common. The other important specification that may or may not be given is the current draw at given fractions of full power and load impedance. This is the amount of power the supply should be capable of delivering for effective amplification (and any look at these values will tell you instantly that the RMS output power of an amplifier is not a terribly good estimation of how much power the amplifier actually requires). If this value is not given, a fairly good estimation of the effective supply power for your set up is to take the output ratings of your amps, and double the value (so for a total of 5KW of amplification potential, a good recommendation would be to have 10KW of supply power). A lack of headroom in this department may not have an obvious effect straight away, but the compression introduced by lack of supply power will become more obvious at higher volumes, and the strain on components will eventually show (in the fact that they will fail sooner than expected). Again, you pays your money, you takes your choice – but the smart money says balance it properly… 😉
Crossovers
Using a single speaker driver to reproduce frequencies across the audible bandwidth is possible, but from a number of standpoints is not very satisfactory, and as the signal level increases, so do the undesirable characteristics of having one driver do all the work. It is generally better by far to have a range of speaker drivers and types, designed to reproduce segments of the total frequency band (ie – large powerful drivers to reproduce the bass end, and small more rigid drivers to reproduce the faster high frequency end). Equally, it would be more efficient if the bass drivers were driven by only the bass part of the signal, and the highs driven by the high part. For this purpose, the crossover was designed.
There are various types of crossover which I will go into in more detail below, but from a system design perspective the first thing to consider is whether to have the crossovers active or passive:
Passive crossovers Unless you build your own speaker boxes, your system will certainly contain a passive crossover system (the only commercial speaker designs exempt from this are ones with single driver types loaded into them – Any full range speaker will usually contain at least 2 driver sizes, and a passive crossover). These are circuits built into the speaker box that (at their most basic) filter out the low frequency signal from the feed to the tweeter driver (also known as a high pass filter as it allows the high frequency to pass, but filter out the low). Again, at it’s most basic level, this would consist of a single capacitor (a capacitor offers high reactance to low frequency energy, thus blocking it). So, if a capacitor acts as a high pass filter, it follows that a coil (which has a basically opposite frequency characteristic to a capacitor) would act to allow the low frequency signal, but block the high (also known as a low pass filter). I will go into the details of designs, and how to calculate the necessary values for these components in the later section on design of speaker cabinets, but they are essentially variations on this theme.
The benefits of using a passive design for your crossover system are mostly in ease of use and setup (once the original design work is done), and the ability to mass produce without requiring too much technical knowledge on the part of the end user. It does however have several significant drawbacks – Firstly, having the crossover filters between the amp and the speaker drivers is fairly inefficient (as you are amplifying the signal, then filtering parts out which takes away some of the signal power). Secondly, the use of some of the more complex (and efficient) filter designs have a tendency to introduce summing distortion in the final reproduction, and thirdly it allows for no fine tuning to take account of venue acoustics. The answer to the above problems is to use:
Active crossovers An active crossover is a dedicated piece of electronics that is placed before your amplifiers in the signal chain. It’s purpose is essentially the same as a passive crossover – ie sending the right frequencies to the right speaker drivers, but it has several advantages:
1) Because the filters are before the amplification stage in the signal chain, they allow a more efficient use of the amplification system (because after the frequencies are filtered, the signal can then be amplified to bring it back up to the input level of the amps, thus using the full power of the amp on the limited frequency band alone).
2) Very complex filter designs can be used, as the crossover points allow for tuning to ameliorate some of the problems with summing etc.
3) The whole speaker system can be tuned to the venue acoustics relatively easily.
4) Active crossovers come in 2,3,4,5 and even 6 way varieties (which allows an extremly high degree of selection for frequency bands being sent to each speaker)It’s main disadvantage is that it requires a bit more knowledge on the part of the user, and more time to set up properly. Each speaker driver type must also be loaded into it’s own cabinet (having 2 types in a cabinet isn’t terribly difficult from a technical perspective, but rather defeats the purpose of using an active network… 😉 ).
I will go into more detail on this subject in the design section, but as a quick reference on the types of crossover you are likely to meet:
First order A first order network is one that produces a 6dB per octave rolloff at the crossover point (ie the filter reduces the power sent to the driver by 6dB for every octave of frequency). This is the most basic (and often used passive) crossover network, and consists of a single component on each branch (ie a capacitor on the signal path to the tweeter, and a coil on the path to the woofer). The slow roll off has a tendency to introduce lobing (where the intersection of the crossover frequency roll-offs produce unwanted peaks at the crossover point).
Second order A second order network has 2 components in each branch (ie a capacitor in series with the tweeter, and a coil linked in parallel with it; and a coil in series with the woofer, with a capacitor linked in parallel). The practical effect is to produce a roll off of 12dB per octave.
Third order Has 3 components in each branch (2 capacitors and a coil for the tweeter, and 2 coils and a capacitor for the woofer). This produces an 18dB per octave roll off.
Fourth order Has (you guessed it) 4 components in each branch, and produces a 24dB per octave roll off.
Butterworth network The most common for passive crossovers, this relates to the values of capacitor and coil used in second, third and fourth order networks (I will go into these values, and how to calculate them in the design section).
Linkwitz-Riley network These are the most efficient designs for higher order networks, using different values than the Butterworth to achieve the crossover point, but resulting in a much higher damping, and thus better crossover performance. Most active networks will be a variation on the 4th order L-R network design.
If you are using an active crossover and shop made speaker boxes though please please please open the boxes up and check for passive crossovers in them – the performance and other benefits from having an active network are totally negated if they are being fed through a passive network post-amplification – all you have to do is re-wire internally so the input jack is connected directly to driver (bypassing the crossover circuit completely – this includes checking for components wired across the speaker terminals. Basically, there should be nothing connected bar the positive and negative connections to the input connector).
You may btw come across speaker systems occasionally that have a woofer/tweeter combination, but no crossover in the box – the reason for this is usually that the tweeters are piezo electric devices, and the low frequency protection to the tweeter is afforded by this fact (a piezo has such high impedance at low frequency that the tweeter is essentially out of the circuit).
Mixers. Equalisation. Compressors, expanders and associated jiggery pokery.
Mixers:
Probably the piece of equipment most people have at least seen, and have some idea of what it does – but just for a re-cap (and for completeness’ sake).
The purpose of a mixer is to take the various input signals (whether they be line level from a CD player, or signal level from a turntable, guitar pickup, mic etc), and mix them together to provide a summed output to the amplification equipment (while providing some control over how those signals are summed). At it’s most basic, it will take the input from (say) 2 turntables, provide monitoring individually for each (using headphones), allow control over the gain on each, and send the result from an output at “line” voltage to be amplified. In practice this would also include at the very least a second output to send to a set of “monitor” speakers (so the DJ could hear the result properly).
Mixers obviously come a good deal more complicated than this, and will allow for a lot of fine control over how the various signals are summed – ie allowing control of pan positions in the stereo output, giving equalisation controls on each signal, allowing more effective monitoring, having signal insert points for external processors, “bus” points for connecting external processing and allowing it to be fed multiple signals (as well as giving convenient output points for stage monitoring – referred to as foldback – allowing the artists on stage to monitor their own instruments properly) – the list of features can be quite long… But the basic premise is doing exactly what it says on the tin – taking input signals and mixing them together… 🙂
Equalisers:
Equalisers are most commonly seen as part of a mixer, but there are also dedicated outboard devices that are intended for various uses in your signal chain. There are various types of equaliser commonly used:
Graphic equaliser Has a set of controls that allow the gain at particular frequency points (set on the device) to be controlled. The frequency points are called “bands”, and on more complex devices can offer quite precise control of the overall sound. The obvious drawback is the space required to include a large number of bands for each mixer channel. They are quite useful for tuning the overall characteristic of the mix though, and are also very useful in combination with a compressor for removal of feedback frequencies (which I will go into more detail on in the compressor section).
Shelving equaliser Usually for low and high (although sometimes a fixed mid is also included) – this is an eq that has a set frequency point, and allows control of the gain at that point – essentially either a low pass, band pass or high pass filter with a gain control. This is the most common form of EQ on DJ mixers, and can be used as a simple cut on particular frequency bands by a DJ (I would recommend discouraging them from using it as a boost however, as the quality of the boost and the lack of precise control quickly leads to distortion – there are far better devices for tuning the overall sound, and there is really no good reason to use them as a boost – that’s what amplifiers are for)
Parametric and semi-parametric equaliser This is the most useful EQ type (and one you will see commonly on large mixing desks). It basically takes the form of a frequency control, a gain control, and a “q” control – the frequency control sets the point in the frequency band that you are altering, the gain is obvious, and the q control sets the width of the frequencies to either side of the control point that you are affecting. This allows precise control over what is added or taken away from the sound, while also being relatively compact in the space it uses (most large mixing desks have a parametric, or semi-parametric eq on each input). Semi-parametric is basically the same, but has a set q for each frequency, and only allows gain control.
These are the most common eq types (there are others, but they are usually found in software rather than hardware), and there are no real hard and fast rules for how to use them – the object is to alter the sound until you achieve the effect you want. The only things I would recommend bearing in mind are: cut rather than boost – eq’s are not for amplifying the signal. They work best if they are used to cut the gain at a particular frequency or frequencies. Amplifiers are for making the signal louder, not eq’s. And if you can’t get the sound you want, and you’ve been trying for ages – zero the eq (ie set it back to completely flat), and start again. It will save you time in the long run…. 🙂
Compressors/expanders/limiters
This is probably the most often mis-used piece of equipment in any sound setup (which is a little bizarre, as it is probably one of the simplest pieces of equipment too… 😉 ) Most often it is to be found being used for “protection” of the audio system – not an entirely ridiculous use, but usually when it is being used for “protection”, it is set up so badly that it it is doing entirely the opposite, and helping destroy the system.
So, what is a compressor?
This one admits of almost a single line answer – it’s an automatic gain control. Simple. What it does is turn the volume up or down using a set of parameters that are configurable – the usual ones are:
Threshold: The signal level at which the gain compensation will start.
Ratio: The amount of compensation applied – a 10:1 ratio for instance will result in gain compensation after the threshold of 10 for every 1 (ie it takes +10dB applied to the input to cause the output to increase by +1dB)
Attack time: The length of time in milliseconds it takes for the gain compensation to cut in after the signal level hits the threshold.
Release time: The length of time in milliseconds after the signal drops below the threshold that it takes for the gain compensation to get back to 1:1
Knee: essentially the shape of the signal – a hard knee has a linear shape with the compensation proceeding in a linear manner after the threshold (and results in an abrupt character to the output), while a soft knee has a more curved shape, resulting in a less abrupt character.
And that’s essentially it. The trouble starts when it is put into a signal chain to do the job of a limiter and is then misconfigured. I will go into the more sensible uses in a moment, but first it’s worth pointing out what a limiter is (and what it does):
A limiter is a compressor set up with a “hard knee”, an infinite compression ratio, zero attack delay, and zero release delay. The threshold can then be used to limit the output to the amplifier system (and so stop the amps from being totally overdriven potentially destroying both them and the speakers connected to them). You can use a dedicated compressor limiter to do this job, but often you will find an active crossover matrix has a built in limiter (on which you just set the threshold), and is capable of doing the job just as well (and without the addition of an extra box to the system). This isn’t a foolproof way of protecting the system (because overdriven input signals will still result in clipping distortion introduced by the limiter – which is still bad), but it does prevent totally overdriving the inputs (which is the quickest way of destroying your amps and speakers by far).
So what are the uses for a compressor?
As a signal conditioner on mixer inputs (most especially mic inputs) to prevent mixer channels from being overdriven by (for instance) artists doing silly things like sticking the mic in their gob and screeching with it thus inserted… 😉
As a mastering effect – a compressor will tend to make quiet sounds louder (if properly configured), keeping the overall level optimised. Mastering software commonly includes a compressor for this purpose (although it is often the case that professional mastering engineers prefer to use manual gain controls rather than a compressor)…
For feedback control in a venue – most commonly in conjunction with some sort of equaliser connected to the side band input. The practical effect of this is that the equaliser can be used to control the compression on particular frequencies (in feedback control, the ones in the venue that are problematic) allowing for a much more natural overall sound than just applying eq to solve the problem would. Most “feedback control” devices are variations on this theme – ie a compressor with one or more eq’s sidebanded.
As a limiter – if you have no other devices already in the signal chain that can do this job, then use a dedicated compressor for it.
As an effect – compressors set to silly values often have uses as audio effects (most especially as a form of distortion effect).
And finally, as a quick aside – what is an expander?
Usually part of a compressor/limiter, an expander is basically the exact opposite of a limiter – ie it prevents any signal of a level lower than the set threshold from getting through. The practical use of this is to cut out hum, or stage rumble from mics etc from the signal – basically you set the threshold to just above the lower limit at which the unwanted sound can be heard, and it will shut off the signal when it is low enough for the unwanted sound to be a problem….
February 13, 2008 at 7:36 pm #1144984Basic Audio Theory
This third section is intended to be a basic introduction and discussion of the various pieces of equipment used in sound reinforcement
Audio Amplifiers
The amplifier is perhaps the most important (and certainly the most ubiquitous) piece of electronics in existence today. In fact, it could easily be argued that without the humble amplifier, most of the advances in electronics from the past 100 years would have been impossible. Equally, it is difficult to imagine a world without the various audio amplifiers that we are surrounded by in everyday life – from the amplifier in our hi-fi’s to the TV, PC, and mobile phone, amplifiers are all around us, and permeate our everyday existence. So what exactly are audio amplifiers?
To answer this question, look back to the previous sections of this how to, and re-imagine the analogue representation of our audio signal. Now, as can hopefully be seen from the previous examples, the linear representations of our audio signal (whether they come from a tiny moving coil as in a phonograph needle, or from a DA conversion circuit in a CD) are necessarily very small (for a standard line level, only 1 or 2 volts maximum, and only a few millivolts for a phono needle). If we are hoping to drive the huge coil/magnet combinations of the average speaker driver, they will obviously need to be far larger. The answer to this problem is the amplifier.
Here, it is worth noting the delineation between what engineers refer to as “signal” level voltages, and “line” level voltages. A signal level voltage is what we refer to when we are talking about the few millivolt signal commonly output by a phonograph, or a guitar pickup etc. These require what we call a “pre-amplifier” to bring them up to the common “line” level voltage (usually 500mV for consumer equipment, and 1-2V for pro equipment). A pre-amplifier is a voltage amplifier (it has no effect on current level) who’s sole purpose is to bring a signal level up to a line level (some pre-amps will also include various conditioning circuits depending on the device the pre-amp is designed for as well). In contrast, a power amplifier is designed to take a line level signal, and amplify it to a corresponding high voltage, and high current signal for the purpose of driving a low impedance speaker coil…
So how do we perform this particular piece of magic? With the help of the humble transistor (it can also be done with vacuum tubes, and many argue it is better done with these devices – the only answer I will give to this assertion is go and count how many recording studios have tube amplifiers fitted for their mastering setups…) The transistor (whether it be JFET, MOS-FET or BJT) is basically a device that can take an input signal at it’s gate (or base for bipolars), and use it essentially as a valve for a more powerful current (in bipolar types) or voltage (for FET’s) across its source-drain (or collector-emitter in bipolars) so producing a larger analogue of the base signal at it’s drain (or emitter). That is essentially an audio amplifier (at it’s most basic). This is an over-simplification, but the analogy should help in giving a working understanding of what the amplifier circuit actually does. Obviously there are many designs and varied ways of putting these transistors together, but I think I can probably say that 99% of designs for power amplifiers today follow the topology made by RCA in 1956 which is the 3 stage design:
1st stage: Usually referred to as the input stage, this is a transconductance (voltage to current) amplifier. It basically buffers the signal and amplifies it into a proportional current signal applied to the low impedance input of the second stage (these are pretty much always differential amplifiers as it allows the convenience of having an inverting input for negative feedback, and decent power supply rejection ratio characteristics).
2nd stage: The voltage amplifier stage (or VA stage). This is a transimpedance (current to voltage) amplifier. It receives the current signal from the input stage, and converts it to a high level voltage signal (and also provides the gain compensation that is critical to overall stability).
3rd stage: The output stage (or OPS). This is basically a current amplifier – it takes the high voltage signal from the VA stage, and amplifies the current to give a near unity voltage gain high current output to the speaker load. There are a variety of ways that this stage can be configured, but it is essentially a bi-directional common-collector amplifier.
Hopefully this has given some insight into what actually happens “under the hood” so to speak in a common power amplifier. If you want to learn more, and are interested in designing your own power amplifiers, I can highly recommend G. Randy Slone’s “High power audio amplifier construction manual”, which goes into this subject in far more depth, and includes practical examples up to a design for an 1100 watt power amp….
As a final note (and with the intent of keeping the reference info slightly separate from the general waffling 🙂 ), I thought I’d finish this section with a rundown of the typical characteristics a manufacturer will give for an amplifier, and what they mean…
Rated power A manufacturer will give a power rating (RMS) at various load impedances (usually 8ohm, 4ohm, and 2ohm). This is the output power measured using a 1KHz signal (generally – it will state if not) that the amplifier produces. This is the power rating that you should use to match your amplifier with your speaker load.
Rated power (bridge mode) Bridging is a way of getting much larger output from an amplifier by taking a stereo amplifier, having one side 180 degrees out of phase with the other, and then connecting the speaker across the high sides (ie the output rails) of each amplifier. A spec sheet will generally give a bridged output rating at 8 and 4 ohm.
Minimum load impedance The minimum impedance of the total speaker load connected to the amplifier (many amps have a minimum load impedance of 2ohm, but I personally tend to avoid using an output load this low for various reasons from inherent large signal nonlinearity in 2 ohm loads to the fact that at a 2ohm load, the components are going to be at the very limit of their thermal cyclic curves which is never good for them. For practical application, I would recommend not going below a 4ohm load, but you pays your money, you takes your choice… 😉 )
Frequency response The frequencies at which the amplifier will provide amplification. For all practical purposes in any amplifier, this will cover the audible range and then some (10Hz-100KHz is from below what you can hear to way way above…)
THD, or Total Harmonic Distortion Expressed as a percentage value, this is the amount of harmonic distortion (ie unwanted additions to the signal) that the amplifier produces. This will typically be around 0.2% for modern solid state amps, and can pretty much be ignored as a spec (Your speaker system will produce far far more distortion than any amplifier in production, and I would defy anybody to pick out a 0.1%THD amp from a 0.2%THD amp in a blind test…) Obviously lower THD is better, but for practical purposes, don’t worry about it too much…
CMRR, or Common Mode Rejection Ratio The ability of the amplifier to filter out “common mode” signals within it’s signal path (common mode signals tend to be EMI, or distortion introduced in the signal path). Usually expressed as a ratio at 1KHz (ie – 55dB would be 55:1). Generally bigger is better.
Slew rate This is the maximum rate of voltage change at the output of the amplifier, and is probably the best indicator of the amplifiers speed (it is usually given in Volts/microsecond). This is obviously important from the point of view of frequency response and signal linearity (if the amplifier can’t follow the signal quickly enough, there will be distortion introduced into the signal), and it would seem that faster is better. This holds true for the most part, but can be taken to ridiculous and possibly detrimental extremes (in which the high frequency instability introduced by an excessively high slew rate outweighs the supposed benefits gained). I’m not going to go into the whole gory detail here however, as for the most part any amplifier available commercially will have an acceptable slew rate for it’s power rating…
Damping factor The ratio of the output stage impedance and the speaker system impedance. The ideal amplifier would be a perfect voltage source to the speaker being driven by it. In the real world however, this doesn’t happen, but we try and get this ratio as high as possible (so the load variation has as little effect on the output voltage as possible). There’s a lot of general waffle on this subject, but my advice is to not worry about it too much…
There are sometimes other specs given for amplifiers, but these are the most common. The other important specification that may or may not be given is the current draw at given fractions of full power and load impedance. This is the amount of power the supply should be capable of delivering for effective amplification (and any look at these values will tell you instantly that the RMS output power of an amplifier is not a terribly good estimation of how much power the amplifier actually requires). If this value is not given, a fairly good estimation of the effective supply power for your set up is to take the output ratings of your amps, and double the value (so for a total of 5KW of amplification potential, a good recommendation would be to have 10KW of supply power). A lack of headroom in this department may not have an obvious effect straight away, but the compression introduced by lack of supply power will become more obvious at higher volumes, and the strain on components will eventually show (in the fact that they will fail sooner than expected). Again, you pays your money, you takes your choice – but the smart money says balance it properly… 😉
Crossovers
Using a single speaker driver to reproduce frequencies across the audible bandwidth is possible, but from a number of standpoints is not very satisfactory, and as the signal level increases, so do the undesirable characteristics of having one driver do all the work. It is generally better by far to have a range of speaker drivers and types, designed to reproduce segments of the total frequency band (ie – large powerful drivers to reproduce the bass end, and small more rigid drivers to reproduce the faster high frequency end). Equally, it would be more efficient if the bass drivers were driven by only the bass part of the signal, and the highs driven by the high part. For this purpose, the crossover was designed.
There are various types of crossover which I will go into in more detail below, but from a system design perspective the first thing to consider is whether to have the crossovers active or passive:
Passive crossovers Unless you build your own speaker boxes, your system will certainly contain a passive crossover system (the only commercial speaker designs exempt from this are ones with single driver types loaded into them – Any full range speaker will usually contain at least 2 driver sizes, and a passive crossover). These are circuits built into the speaker box that (at their most basic) filter out the low frequency signal from the feed to the tweeter driver (also known as a high pass filter as it allows the high frequency to pass, but filter out the low). Again, at it’s most basic level, this would consist of a single capacitor (a capacitor offers high reactance to low frequency energy, thus blocking it). So, if a capacitor acts as a high pass filter, it follows that a coil (which has a basically opposite frequency characteristic to a capacitor) would act to allow the low frequency signal, but block the high (also known as a low pass filter). I will go into the details of designs, and how to calculate the necessary values for these components in the later section on design of speaker cabinets, but they are essentially variations on this theme.
The benefits of using a passive design for your crossover system are mostly in ease of use and setup (once the original design work is done), and the ability to mass produce without requiring too much technical knowledge on the part of the end user. It does however have several significant drawbacks – Firstly, having the crossover filters between the amp and the speaker drivers is fairly inefficient (as you are amplifying the signal, then filtering parts out which takes away some of the signal power). Secondly, the use of some of the more complex (and efficient) filter designs have a tendency to introduce summing distortion in the final reproduction, and thirdly it allows for no fine tuning to take account of venue acoustics. The answer to the above problems is to use:
Active crossovers An active crossover is a dedicated piece of electronics that is placed before your amplifiers in the signal chain. It’s purpose is essentially the same as a passive crossover – ie sending the right frequencies to the right speaker drivers, but it has several advantages:
1) Because the filters are before the amplification stage in the signal chain, they allow a more efficient use of the amplification system (because after the frequencies are filtered, the signal can then be amplified to bring it back up to the input level of the amps, thus using the full power of the amp on the limited frequency band alone).
2) Very complex filter designs can be used, as the crossover points allow for tuning to ameliorate some of the problems with summing etc.
3) The whole speaker system can be tuned to the venue acoustics relatively easily.
4) Active crossovers come in 2,3,4,5 and even 6 way varieties (which allows an extremly high degree of selection for frequency bands being sent to each speaker)It’s main disadvantage is that it requires a bit more knowledge on the part of the user, and more time to set up properly. Each speaker driver type must also be loaded into it’s own cabinet (having 2 types in a cabinet isn’t terribly difficult from a technical perspective, but rather defeats the purpose of using an active network… 😉 ).
I will go into more detail on this subject in the design section, but as a quick reference on the types of crossover you are likely to meet:
First order A first order network is one that produces a 6dB per octave rolloff at the crossover point (ie the filter reduces the power sent to the driver by 6dB for every octave of frequency). This is the most basic (and often used passive) crossover network, and consists of a single component on each branch (ie a capacitor on the signal path to the tweeter, and a coil on the path to the woofer). The slow roll off has a tendency to introduce lobing (where the intersection of the crossover frequency roll-offs produce unwanted peaks at the crossover point).
Second order A second order network has 2 components in each branch (ie a capacitor in series with the tweeter, and a coil linked in parallel with it; and a coil in series with the woofer, with a capacitor linked in parallel). The practical effect is to produce a roll off of 12dB per octave.
Third order Has 3 components in each branch (2 capacitors and a coil for the tweeter, and 2 coils and a capacitor for the woofer). This produces an 18dB per octave roll off.
Fourth order Has (you guessed it) 4 components in each branch, and produces a 24dB per octave roll off.
Butterworth network The most common for passive crossovers, this relates to the values of capacitor and coil used in second, third and fourth order networks (I will go into these values, and how to calculate them in the design section).
Linkwitz-Riley network These are the most efficient designs for higher order networks, using different values than the Butterworth to achieve the crossover point, but resulting in a much higher damping, and thus better crossover performance. Most active networks will be a variation on the 4th order L-R network design.
If you are using an active crossover and shop made speaker boxes though please please please open the boxes up and check for passive crossovers in them – the performance and other benefits from having an active network are totally negated if they are being fed through a passive network post-amplification – all you have to do is re-wire internally so the input jack is connected directly to driver (bypassing the crossover circuit completely – this includes checking for components wired across the speaker terminals. Basically, there should be nothing connected bar the positive and negative connections to the input connector).
You may btw come across speaker systems occasionally that have a woofer/tweeter combination, but no crossover in the box – the reason for this is usually that the tweeters are piezo electric devices, and the low frequency protection to the tweeter is afforded by this fact (a piezo has such high impedance at low frequency that the tweeter is essentially out of the circuit).
Mixers. Equalisation. Compressors, expanders and associated jiggery pokery.
Mixers:
Probably the piece of equipment most people have at least seen, and have some idea of what it does – but just for a re-cap (and for completeness’ sake).
The purpose of a mixer is to take the various input signals (whether they be line level from a CD player, or signal level from a turntable, guitar pickup, mic etc), and mix them together to provide a summed output to the amplification equipment (while providing some control over how those signals are summed). At it’s most basic, it will take the input from (say) 2 turntables, provide monitoring individually for each (using headphones), allow control over the gain on each, and send the result from an output at “line” voltage to be amplified. In practice this would also include at the very least a second output to send to a set of “monitor” speakers (so the DJ could hear the result properly).
Mixers obviously come a good deal more complicated than this, and will allow for a lot of fine control over how the various signals are summed – ie allowing control of pan positions in the stereo output, giving equalisation controls on each signal, allowing more effective monitoring, having signal insert points for external processors, “bus” points for connecting external processing and allowing it to be fed multiple signals (as well as giving convenient output points for stage monitoring – referred to as foldback – allowing the artists on stage to monitor their own instruments properly) – the list of features can be quite long… But the basic premise is doing exactly what it says on the tin – taking input signals and mixing them together… 🙂
Equalisers:
Equalisers are most commonly seen as part of a mixer, but there are also dedicated outboard devices that are intended for various uses in your signal chain. There are various types of equaliser commonly used:
Graphic equaliser Has a set of controls that allow the gain at particular frequency points (set on the device) to be controlled. The frequency points are called “bands”, and on more complex devices can offer quite precise control of the overall sound. The obvious drawback is the space required to include a large number of bands for each mixer channel. They are quite useful for tuning the overall characteristic of the mix though, and are also very useful in combination with a compressor for removal of feedback frequencies (which I will go into more detail on in the compressor section).
Shelving equaliser Usually for low and high (although sometimes a fixed mid is also included) – this is an eq that has a set frequency point, and allows control of the gain at that point – essentially either a low pass, band pass or high pass filter with a gain control. This is the most common form of EQ on DJ mixers, and can be used as a simple cut on particular frequency bands by a DJ (I would recommend discouraging them from using it as a boost however, as the quality of the boost and the lack of precise control quickly leads to distortion – there are far better devices for tuning the overall sound, and there is really no good reason to use them as a boost – that’s what amplifiers are for)
Parametric and semi-parametric equaliser This is the most useful EQ type (and one you will see commonly on large mixing desks). It basically takes the form of a frequency control, a gain control, and a “q” control – the frequency control sets the point in the frequency band that you are altering, the gain is obvious, and the q control sets the width of the frequencies to either side of the control point that you are affecting. This allows precise control over what is added or taken away from the sound, while also being relatively compact in the space it uses (most large mixing desks have a parametric, or semi-parametric eq on each input). Semi-parametric is basically the same, but has a set q for each frequency, and only allows gain control.
These are the most common eq types (there are others, but they are usually found in software rather than hardware), and there are no real hard and fast rules for how to use them – the object is to alter the sound until you achieve the effect you want. The only things I would recommend bearing in mind are: cut rather than boost – eq’s are not for amplifying the signal. They work best if they are used to cut the gain at a particular frequency or frequencies. Amplifiers are for making the signal louder, not eq’s. And if you can’t get the sound you want, and you’ve been trying for ages – zero the eq (ie set it back to completely flat), and start again. It will save you time in the long run…. 🙂
Compressors/expanders/limiters
This is probably the most often mis-used piece of equipment in any sound setup (which is a little bizarre, as it is probably one of the simplest pieces of equipment too… 😉 ) Most often it is to be found being used for “protection” of the audio system – not an entirely ridiculous use, but usually when it is being used for “protection”, it is set up so badly that it it is doing entirely the opposite, and helping destroy the system.
So, what is a compressor?
This one admits of almost a single line answer – it’s an automatic gain control. Simple. What it does is turn the volume up or down using a set of parameters that are configurable – the usual ones are:
Threshold: The signal level at which the gain compensation will start.
Ratio: The amount of compensation applied – a 10:1 ratio for instance will result in gain compensation after the threshold of 10 for every 1 (ie it takes +10dB applied to the input to cause the output to increase by +1dB)
Attack time: The length of time in milliseconds it takes for the gain compensation to cut in after the signal level hits the threshold.
Release time: The length of time in milliseconds after the signal drops below the threshold that it takes for the gain compensation to get back to 1:1
Knee: essentially the shape of the signal – a hard knee has a linear shape with the compensation proceeding in a linear manner after the threshold (and results in an abrupt character to the output), while a soft knee has a more curved shape, resulting in a less abrupt character.
And that’s essentially it. The trouble starts when it is put into a signal chain to do the job of a limiter and is then misconfigured. I will go into the more sensible uses in a moment, but first it’s worth pointing out what a limiter is (and what it does):
A limiter is a compressor set up with a “hard knee”, an infinite compression ratio, zero attack delay, and zero release delay. The threshold can then be used to limit the output to the amplifier system (and so stop the amps from being totally overdriven potentially destroying both them and the speakers connected to them). You can use a dedicated compressor limiter to do this job, but often you will find an active crossover matrix has a built in limiter (on which you just set the threshold), and is capable of doing the job just as well (and without the addition of an extra box to the system). This isn’t a foolproof way of protecting the system (because overdriven input signals will still result in clipping distortion introduced by the limiter – which is still bad), but it does prevent totally overdriving the inputs (which is the quickest way of destroying your amps and speakers by far).
So what are the uses for a compressor?
As a signal conditioner on mixer inputs (most especially mic inputs) to prevent mixer channels from being overdriven by (for instance) artists doing silly things like sticking the mic in their gob and screeching with it thus inserted… 😉
As a mastering effect – a compressor will tend to make quiet sounds louder (if properly configured), keeping the overall level optimised. Mastering software commonly includes a compressor for this purpose (although it is often the case that professional mastering engineers prefer to use manual gain controls rather than a compressor)…
For feedback control in a venue – most commonly in conjunction with some sort of equaliser connected to the side band input. The practical effect of this is that the equaliser can be used to control the compression on particular frequencies (in feedback control, the ones in the venue that are problematic) allowing for a much more natural overall sound than just applying eq to solve the problem would. Most “feedback control” devices are variations on this theme – ie a compressor with one or more eq’s sidebanded.
As a limiter – if you have no other devices already in the signal chain that can do this job, then use a dedicated compressor for it.
As an effect – compressors set to silly values often have uses as audio effects (most especially as a form of distortion effect).
And finally, as a quick aside – what is an expander?
Usually part of a compressor/limiter, an expander is basically the exact opposite of a limiter – ie it prevents any signal of a level lower than the set threshold from getting through. The practical use of this is to cut out hum, or stage rumble from mics etc from the signal – basically you set the threshold to just above the lower limit at which the unwanted sound can be heard, and it will shut off the signal when it is low enough for the unwanted sound to be a problem….
February 13, 2008 at 8:24 pm #1124065Raj wrote:Shelving equaliser Usually for low and high (although sometimes a fixed mid is also included) – this is an eq that has a set frequency point, and allows control of the gain at that point – essentially either a low pass, band pass or high pass filter with a gain control. This is the most common form of EQ on DJ mixers, and can be used as a simple cut on particular frequency bands by a DJ (I would recommend discouraging them from using it as a boost however, as the quality of the boost and the lack of precise control quickly leads to distortion – there are far better devices for tuning the overall sound, and there is really no good reason to use them as a boost – that’s what amplifiers are for)I totally agree.
I do not understand why on DJ mixers the shelf EQ doesn’t stop at 0 dB and only allows dB reduction ? :you_crazy
Cutting is fine – in fact it is a great effect when mixing – but you should NEVER boost.
Only red line monkey’s do that :you_crazy
And thanks for another great and informative article.
:group_hug
February 13, 2008 at 8:24 pm #1144983Raj wrote:Shelving equaliser Usually for low and high (although sometimes a fixed mid is also included) – this is an eq that has a set frequency point, and allows control of the gain at that point – essentially either a low pass, band pass or high pass filter with a gain control. This is the most common form of EQ on DJ mixers, and can be used as a simple cut on particular frequency bands by a DJ (I would recommend discouraging them from using it as a boost however, as the quality of the boost and the lack of precise control quickly leads to distortion – there are far better devices for tuning the overall sound, and there is really no good reason to use them as a boost – that’s what amplifiers are for)I totally agree.
I do not understand why on DJ mixers the shelf EQ doesn’t stop at 0 dB and only allows dB reduction ? :you_crazy
Cutting is fine – in fact it is a great effect when mixing – but you should NEVER boost.
Only red line monkey’s do that :you_crazy
And thanks for another great and informative article.
:group_hug
February 13, 2008 at 9:35 pm #1124055Anonymous
canny make head nor tail of that lot???
i just twiddle knobs till it sounds ok, make sure theres no red lights on stuff & just keep an eye out for smoke n smells of burning.
February 13, 2008 at 9:35 pm #1144973canny make head nor tail of that lot???
i just twiddle knobs till it sounds ok, make sure theres no red lights on stuff & just keep an eye out for smoke n smells of burning.
June 1, 2008 at 9:20 am #1124059Basic Audio Theory
This final part of the theory section will focus on the engineering, design and construction techniques used in producing (good…🙂) Loudspeaker cabinets
The Final push – Loudspeakers. The whys and wherefores…
So… We’ve had a whirlwind tour of the basics of audio physics, seen how audio is manipulated for the purpose of amplification, and had a whistlestop rundown of some of the common pieces of equipment you will come across when engineering audio. There is only one piece missing, and that is the reproduction of the kinetic energy (in a hugely amplified state hopefully), that made up our original waveform. Putting aside for now any equalisation or processing that you may want to perform on the resulting sound, the aim of any design brief for a PA system remains the same from an audio point of view – we want to take our input sound, and reproduce it in as linear a way as possible (remember the term linearity is used here to describe the faithfulness to the input signal at the output – we want our reproduction equipment to amplify the sound without colouring it in any way).
The last piece of our engineering challenge is the Loudspeaker, which we will use to create the longitudinal pressure waves our hearing then interprets as sound. There are a number of different designs of speaker driver available nowadays (from flat panels that use exciters to make them vibrate to the more common transducers that most people are familiar with). I am going to concentrate on transducers as the method of reproduction, as it is the most efficient way to large signal reproduction (which is the reason for this article) – the above website is a good place to start if you are interested in panel speakers (and of course Google is your friend for that research too… 🙂 ).
As a quick note, the efficiency and accuracy of your speaker system is potentially the area in which good design and construction will pay off the most in the whole design process. While your electronic wizardry, and amplification equipment will be anything up to 90% efficient, your speaker system is likely to be at best 10% efficient, and at worst (hopefully) as low as 1-2%. A quick bit of basic maths will tell you that a small gain in the efficiency of the speaker system will translate into a large gain in the overall system efficiency, whereas a large gain in the rest of the equipment efficiency will have a far less pronounced effect…. It makes sense then to concentrate a good deal of our effort on the speakers…
So what is a transducer, how does it work (and why is it so inefficient)?
A transducer is essentially a linear motor connected to a diaphragm, as pictured above. The audio signal (which is an AC representation of our sound using time versus frequency) is applied at the copper coil connection – which (if you remember your O-level physics) magnetises the coil with the coil polarity being determined by the polarity of the AC signal. This is then either repelled or attracted to the large magnetic field in which it sits (created by the bloody huge magnetic ring at the back of the speaker). This in turn pushes the diaphragm in and out which performs another amplification of the small kinetic movement into a much larger one, and creates pressure waves that radiate out (thus causing the differentials in pressure that we experience as sound). NB – a useful way to test the operation of a speaker coil if it is suspected of being faulty is to connect a small (1.5V AA will do) battery across it’s terminals. The DC current is enough to activate the coil and you will hear a “pop” as the coil repels and moves forwards…So far so good. We have a surface area that will create our sound wave, and that is what we are looking for. So why all this nonsense with speaker box designs and whatnot? Surely we are just adding complexity for no good reason, and we should just have a bunch of drivers together to reproduce our sound?
Unfortunately, the transducer (or speaker driver) has 2 very serious flaws from the sound reproduction point of view:
1) A speaker driver (like alll mechanical devices) has a frequency of
resonance, at which it requires far less power to effect movement than at other frequencies. This results in a very unnatural peak in the response curve of the speaker at the frequency of resonance (and also at the harmonic frequencies of the fundamental frequency), and so affects the linearity of the system. Remember, we want our speakers to add nothing apart from volume to the sound.
2) A speaker driver has an inverse pressure wave present on the other side of the diaphragm, which interferes with the propagation of the sound wave from the front side of the diaphragm, and causes unnatural peaks and troughs (correctly termed “nodes” and “antinodes”) in the reproduction due to this interference from one side to the other. It also causes a severe drop in the efficiency of the speakers amplification potential.
The first problem could be solved by putting a comb filter onto each driver, and damping down the energy supplied at the resonant and harmonic frequencies – a fairly complex solution, but one that would have the desired effect. The second problem is only solved by blocking the interaction of the opposing pressures. The easiest way to do this is to have a solid barrier preventing (or at least minimising) the interaction. You may have heard of the term “infinite baffle” in relation to speakers (and in most cases it’s likely being used incorrectly) – what is meant by the term infinite baffle is a barrier of a size large enough that the interaction is impossible, and the speaker is therefore not affected by the inverse waves created at it’s rear. An infinite baffle is technically an impossibility (as it would require a baffle, or barrier of infinite size), so the term is often used to denote a technique that creates a barrier that for all practical purposes might as well be infinite (usually this is done in an exuberant manner, with spectacular claims concerning a particular piece of cabinet design technology. Have a good read of this website if you would like a rundown of the various cabinet design camps, and a balanced view of their effectiveness – as well as a description of probably the closest design to “infinite baffle” practicably possible – definetly going to try this one when I get the chance and the right room 🙂 ).
The most practical solution (because in sound engineering there is never a “perfect ” solution – it is always a case of balancing the advantages and disadvantages – especially true for PA systems that are required to be portable) is the speaker cabinet – a box, or enclosure of some kind that minimises the interference of the inverse waves, and also provides some resistance (or impedance as it is correctly termed) to the speaker diaphragm, damping it’s tendency to increase it’s output at it’s resonant frequency. So in the next section, we will start examining the various enclosure types, and the objective merits and demerits of the design (and no doubt start some heated debate, as every cabinet builder has his/her favourite)… 🙂
June 1, 2008 at 9:20 am #1144977Basic Audio Theory
This final part of the theory section will focus on the engineering, design and construction techniques used in producing (good…🙂) Loudspeaker cabinets
The Final push – Loudspeakers. The whys and wherefores…
So… We’ve had a whirlwind tour of the basics of audio physics, seen how audio is manipulated for the purpose of amplification, and had a whistlestop rundown of some of the common pieces of equipment you will come across when engineering audio. There is only one piece missing, and that is the reproduction of the kinetic energy (in a hugely amplified state hopefully), that made up our original waveform. Putting aside for now any equalisation or processing that you may want to perform on the resulting sound, the aim of any design brief for a PA system remains the same from an audio point of view – we want to take our input sound, and reproduce it in as linear a way as possible (remember the term linearity is used here to describe the faithfulness to the input signal at the output – we want our reproduction equipment to amplify the sound without colouring it in any way).
The last piece of our engineering challenge is the Loudspeaker, which we will use to create the longitudinal pressure waves our hearing then interprets as sound. There are a number of different designs of speaker driver available nowadays (from flat panels that use exciters to make them vibrate to the more common transducers that most people are familiar with). I am going to concentrate on transducers as the method of reproduction, as it is the most efficient way to large signal reproduction (which is the reason for this article) – the above website is a good place to start if you are interested in panel speakers (and of course Google is your friend for that research too… 🙂 ).
As a quick note, the efficiency and accuracy of your speaker system is potentially the area in which good design and construction will pay off the most in the whole design process. While your electronic wizardry, and amplification equipment will be anything up to 90% efficient, your speaker system is likely to be at best 10% efficient, and at worst (hopefully) as low as 1-2%. A quick bit of basic maths will tell you that a small gain in the efficiency of the speaker system will translate into a large gain in the overall system efficiency, whereas a large gain in the rest of the equipment efficiency will have a far less pronounced effect…. It makes sense then to concentrate a good deal of our effort on the speakers…
So what is a transducer, how does it work (and why is it so inefficient)?
A transducer is essentially a linear motor connected to a diaphragm, as pictured above. The audio signal (which is an AC representation of our sound using time versus frequency) is applied at the copper coil connection – which (if you remember your O-level physics) magnetises the coil with the coil polarity being determined by the polarity of the AC signal. This is then either repelled or attracted to the large magnetic field in which it sits (created by the bloody huge magnetic ring at the back of the speaker). This in turn pushes the diaphragm in and out which performs another amplification of the small kinetic movement into a much larger one, and creates pressure waves that radiate out (thus causing the differentials in pressure that we experience as sound). NB – a useful way to test the operation of a speaker coil if it is suspected of being faulty is to connect a small (1.5V AA will do) battery across it’s terminals. The DC current is enough to activate the coil and you will hear a “pop” as the coil repels and moves forwards…So far so good. We have a surface area that will create our sound wave, and that is what we are looking for. So why all this nonsense with speaker box designs and whatnot? Surely we are just adding complexity for no good reason, and we should just have a bunch of drivers together to reproduce our sound?
Unfortunately, the transducer (or speaker driver) has 2 very serious flaws from the sound reproduction point of view:
1) A speaker driver (like alll mechanical devices) has a frequency of
resonance, at which it requires far less power to effect movement than at other frequencies. This results in a very unnatural peak in the response curve of the speaker at the frequency of resonance (and also at the harmonic frequencies of the fundamental frequency), and so affects the linearity of the system. Remember, we want our speakers to add nothing apart from volume to the sound.
2) A speaker driver has an inverse pressure wave present on the other side of the diaphragm, which interferes with the propagation of the sound wave from the front side of the diaphragm, and causes unnatural peaks and troughs (correctly termed “nodes” and “antinodes”) in the reproduction due to this interference from one side to the other. It also causes a severe drop in the efficiency of the speakers amplification potential.
The first problem could be solved by putting a comb filter onto each driver, and damping down the energy supplied at the resonant and harmonic frequencies – a fairly complex solution, but one that would have the desired effect. The second problem is only solved by blocking the interaction of the opposing pressures. The easiest way to do this is to have a solid barrier preventing (or at least minimising) the interaction. You may have heard of the term “infinite baffle” in relation to speakers (and in most cases it’s likely being used incorrectly) – what is meant by the term infinite baffle is a barrier of a size large enough that the interaction is impossible, and the speaker is therefore not affected by the inverse waves created at it’s rear. An infinite baffle is technically an impossibility (as it would require a baffle, or barrier of infinite size), so the term is often used to denote a technique that creates a barrier that for all practical purposes might as well be infinite (usually this is done in an exuberant manner, with spectacular claims concerning a particular piece of cabinet design technology. Have a good read of this website if you would like a rundown of the various cabinet design camps, and a balanced view of their effectiveness – as well as a description of probably the closest design to “infinite baffle” practicably possible – definetly going to try this one when I get the chance and the right room 🙂 ).
The most practical solution (because in sound engineering there is never a “perfect ” solution – it is always a case of balancing the advantages and disadvantages – especially true for PA systems that are required to be portable) is the speaker cabinet – a box, or enclosure of some kind that minimises the interference of the inverse waves, and also provides some resistance (or impedance as it is correctly termed) to the speaker diaphragm, damping it’s tendency to increase it’s output at it’s resonant frequency. So in the next section, we will start examining the various enclosure types, and the objective merits and demerits of the design (and no doubt start some heated debate, as every cabinet builder has his/her favourite)… 🙂
June 4, 2008 at 10:47 am #1124069MrAHC;194376 wrote:canny make head nor tail of that lot???i just twiddle knobs till it sounds ok, make sure theres no red lights on stuff & just keep an eye out for smoke n smells of burning.
the red lights should be flashing slightly then you no your system is running at its peak not on constant like you say…:wink:
June 4, 2008 at 10:47 am #1144986MrAHC;194376 wrote:canny make head nor tail of that lot???i just twiddle knobs till it sounds ok, make sure theres no red lights on stuff & just keep an eye out for smoke n smells of burning.
the red lights should be flashing slightly then you no your system is running at its peak not on constant like you say…:wink:
June 4, 2008 at 10:52 am #1124070ive got city and guilds part 1 and 2 in sound engiering an i can only just understand half of that:yawn:…shoulda paid more atention i supose!!
June 4, 2008 at 10:52 am #1144987ive got city and guilds part 1 and 2 in sound engiering an i can only just understand half of that:yawn:…shoulda paid more atention i supose!!
June 5, 2008 at 6:32 am #1124060d.r.e.a.m wrote:ive got city and guilds part 1 and 2 in sound engiering an i can only just understand half of that:yawn:…shoulda paid more atention i supose!!Sorry mate – I’m trying to make it accessible, but getting the info from my head onto paper (or screen) is proving a little more challenging than I expected. Trouble is there is a lot of stuff that to me is second nature, but isn’t necessarily obvious unless you have a background in electrical engineering of some type. Part of the reason for posting it here first is to get some comments on anything people are finding hard to understand (I’m going to be including an index and glossary at the end though, so hopefully that will make it a bit easier to reference).
I’m kind of expecting that most people will find the theory section hard to take in all at once – the idea is that it can be used as a reference to the more practical parts later on…
June 5, 2008 at 6:32 am #1144978d.r.e.a.m wrote:ive got city and guilds part 1 and 2 in sound engiering an i can only just understand half of that:yawn:…shoulda paid more atention i supose!!Sorry mate – I’m trying to make it accessible, but getting the info from my head onto paper (or screen) is proving a little more challenging than I expected. Trouble is there is a lot of stuff that to me is second nature, but isn’t necessarily obvious unless you have a background in electrical engineering of some type. Part of the reason for posting it here first is to get some comments on anything people are finding hard to understand (I’m going to be including an index and glossary at the end though, so hopefully that will make it a bit easier to reference).
I’m kind of expecting that most people will find the theory section hard to take in all at once – the idea is that it can be used as a reference to the more practical parts later on…
June 27, 2008 at 10:17 pm #1124056Hey that guide is awesome, i must admit i am on my way to having an engineering degree, but if just scanned through most of the above and more or less understand it all.
Im looking to build a new sound system for myself with some dirty big bass bins and decent mid/high speakers as i play a lot of house parties and friends party’s etc, and my new love…. Dubstep!
This has given me a nice basic intro to what i need to consider before going on a fun filled journey into soldering wire speakers and sound, roughly! im going to read up a bit more on soundsystems and at the moment i think il be looking at using passive crossovers as active sound a little too complicated for my first home build rig!
Anyways il try keep you all updated on how things go mabe post some pics etc.. :bounce_fl keep on raving keep on raving!!!
June 27, 2008 at 10:17 pm #1144974Hey that guide is awesome, i must admit i am on my way to having an engineering degree, but if just scanned through most of the above and more or less understand it all.
Im looking to build a new sound system for myself with some dirty big bass bins and decent mid/high speakers as i play a lot of house parties and friends party’s etc, and my new love…. Dubstep!
This has given me a nice basic intro to what i need to consider before going on a fun filled journey into soldering wire speakers and sound, roughly! im going to read up a bit more on soundsystems and at the moment i think il be looking at using passive crossovers as active sound a little too complicated for my first home build rig!
Anyways il try keep you all updated on how things go mabe post some pics etc.. :bounce_fl keep on raving keep on raving!!!
July 25, 2008 at 8:06 pm #1124076is this guide going to continue here or is it already being posted elsewhere
cheers
July 25, 2008 at 8:06 pm #1144994is this guide going to continue here or is it already being posted elsewhere
cheers
August 15, 2008 at 11:11 pm #1124061It’s being continued here (I have just been really busy over the summer, and haven’t got as much of it done as I’d like)….
Last party of the year is september though, and hopefully I’ll get more of a layover this year (and being entirely honest, hopefully I’ll get my arse in gear properly and get it done :wink:)
It is coming though raaaraaaraaa
August 15, 2008 at 11:11 pm #1144979It’s being continued here (I have just been really busy over the summer, and haven’t got as much of it done as I’d like)….
Last party of the year is september though, and hopefully I’ll get more of a layover this year (and being entirely honest, hopefully I’ll get my arse in gear properly and get it done :wink:)
It is coming though raaaraaaraaa
-
AuthorPosts
{kind=link}
{kind=link}
- You must be logged in to reply to this topic.
› Forums › Music › Sound Engineering › How to Build a Sound System